

Homework Answers
Margin attained is the minimum distance between the hyperplane and the points.
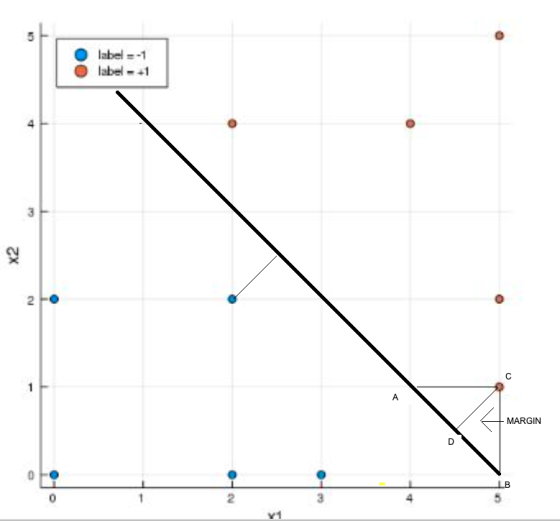
The line shown in between is the hyperplane which divides both the classes and margin is the smallest distance between any point on either side of the hyperplane/line and the hyperplane. Hyperplane/line should be equidistant from the nearest points on both sides.
Margin = CD(see the figure)
We know 



As,


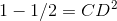

Margin = CD = 0.70710678118
Add Answer to:
Problem 1 Bookmark this page Problem 1. Linear Classification Consider a labeled training set shown in...
Problem 4 True or False A Bookmark this page Instructions: Be very careful with the multiple choice questions below. Some are "choose all that apply," and many tests your knowledge of when pa...
 Problem 4 True or False A Bookmark this page Instructions: Be very careful with the multiple choice questions below. Some are "choose all that apply," and many tests your knowledge of when particular statements apply As in the rest of this exam, only your last submission will count. 1 point possible (graded, results hidden) The likelihood ratio test is used to obtain a test with non-asymptotic level o True O False Submit You have used 0 of 3 attempts Save...
Problem 4 True or False A Bookmark this page Instructions: Be very careful with the multiple choice questions below. Some are "choose all that apply," and many tests your knowledge of when particular statements apply As in the rest of this exam, only your last submission will count. 1 point possible (graded, results hidden) The likelihood ratio test is used to obtain a test with non-asymptotic level o True O False Submit You have used 0 of 3 attempts Save...
4. Setup: Suppose you have observations X1,X2,X3,X4,X5 which are i.i.d. draws from a Gaussian distribution with...
 4.
Setup:
Suppose you have observations X1,X2,X3,X4,X5 which are i.i.d.
draws from a Gaussian distribution with unknown mean μ and unknown
variance σ2.
Given Facts:
You are given the following:
15∑i=15Xi=0.90,15∑i=15X2i=1.31
Bookmark this page Setup: Suppose you have observations X1, X2, X3, X4, X5 which are i.i.d. draws from a Gaussian distribution with unknown mean u and unknown variance o? Given Facts: You are given the following: x=030, =1:1 Choose a test 1 point possible (graded, results hidden) To test...
4.
Setup:
Suppose you have observations X1,X2,X3,X4,X5 which are i.i.d.
draws from a Gaussian distribution with unknown mean μ and unknown
variance σ2.
Given Facts:
You are given the following:
15∑i=15Xi=0.90,15∑i=15X2i=1.31
Bookmark this page Setup: Suppose you have observations X1, X2, X3, X4, X5 which are i.i.d. draws from a Gaussian distribution with unknown mean u and unknown variance o? Given Facts: You are given the following: x=030, =1:1 Choose a test 1 point possible (graded, results hidden) To test...
1 Bookmark this page Setup: For all problems on this page, suppose you have data X],...,x...
 1 Bookmark this page Setup: For all problems on this page, suppose you have data X],...,x . N (0,1) that is a random sample of identically and independently distributed standard normal random variables. Useful facts: The following facts might be useful: For a standard normal random variable X1, we have: E[X] =0, E[X{1=1, E(X) = 3. Sample mean 1.5 points possible (graded, results hidden) Consider the sample mean: X = x + X2+...+X,). What are the mean E [Xn] and...
1 Bookmark this page Setup: For all problems on this page, suppose you have data X],...,x . N (0,1) that is a random sample of identically and independently distributed standard normal random variables. Useful facts: The following facts might be useful: For a standard normal random variable X1, we have: E[X] =0, E[X{1=1, E(X) = 3. Sample mean 1.5 points possible (graded, results hidden) Consider the sample mean: X = x + X2+...+X,). What are the mean E [Xn] and...
1. Implicit hypothesis testing Homework due Jul 29, 2020 07:59 HKT Bookmark this page Given n...
 1. Implicit hypothesis testing Homework due Jul 29, 2020 07:59 HKT Bookmark this page Given n i.i.d. samples X1,..., X, N (u,02) with p ER and op > 0, we want to find a test with asymptotic level 5% for the hypotheses (7.1) Η :μοσ vs H, :μ<σ. (a) 1 point possible (graded) As a first step, define the maximum likelihood estimators ů = Xn, 32 = (X: – 8.)? Give a function g(x,y) such that P 9(î, o?) -0....
1. Implicit hypothesis testing Homework due Jul 29, 2020 07:59 HKT Bookmark this page Given n i.i.d. samples X1,..., X, N (u,02) with p ER and op > 0, we want to find a test with asymptotic level 5% for the hypotheses (7.1) Η :μοσ vs H, :μ<σ. (a) 1 point possible (graded) As a first step, define the maximum likelihood estimators ů = Xn, 32 = (X: – 8.)? Give a function g(x,y) such that P 9(î, o?) -0....
Consider the training examples shown in the table below for a binary classification problem. (a) What...
 Consider the training examples shown in the table below for a binary classification problem. (a) What is the entropy of this collection of training examples with respect to the positive class? (b) What are the information gains of a1 and a2 relative to these training examples? (c) For a3, which is a continuous attribute, compute the information gain for every possible split. (d) What is the best split (among a1 a2, and a3) according to the information gain? (e) What...
Consider the training examples shown in the table below for a binary classification problem. (a) What is the entropy of this collection of training examples with respect to the positive class? (b) What are the information gains of a1 and a2 relative to these training examples? (c) For a3, which is a continuous attribute, compute the information gain for every possible split. (d) What is the best split (among a1 a2, and a3) according to the information gain? (e) What...
2. Biased and unbiased estimation for variance of Bernoulli variables A Bookmark this page 2 points...
 2. Biased and unbiased estimation for variance of Bernoulli variables A Bookmark this page 2 points possible (graded) Let X1, X, bed. Bernoull random variables, with unknown parameter PE (0,1). The aim of this exercise is to estimate the common variance of the X First, recall what Var (X) is for Bernoulli random variables. Var (X) - Let X, be the sample average of the Xi. X. - 3x Interested in finding an estimator for Var(X), and propose to use...
2. Biased and unbiased estimation for variance of Bernoulli variables A Bookmark this page 2 points possible (graded) Let X1, X, bed. Bernoull random variables, with unknown parameter PE (0,1). The aim of this exercise is to estimate the common variance of the X First, recall what Var (X) is for Bernoulli random variables. Var (X) - Let X, be the sample average of the Xi. X. - 3x Interested in finding an estimator for Var(X), and propose to use...
8. Exercise: Counting committees Bookmark this page Exercise: Counting committees 0.0/2.0 points (graded) We start with...
 8. Exercise: Counting committees Bookmark this page Exercise: Counting committees 0.0/2.0 points (graded) We start with a pool of n people. A chaired committee consists of k 1 members, out of whom one member is designated as the chairperson. The expression k(can be interpreted as the number of possible chaired committees with k members. This is because we have choices for the k members, and once the members are chosen, there are then k choices for the chairperson. Thus, is...
8. Exercise: Counting committees Bookmark this page Exercise: Counting committees 0.0/2.0 points (graded) We start with a pool of n people. A chaired committee consists of k 1 members, out of whom one member is designated as the chairperson. The expression k(can be interpreted as the number of possible chaired committees with k members. This is because we have choices for the k members, and once the members are chosen, there are then k choices for the chairperson. Thus, is...
in a Bayesian view. Consider the prior π(a)-1 for all a e R Consider a Gaussian linear model Y = aX+ E Determine whether each of the following statements is true or false. π(a) a uniform prior. (1) (...
 in a Bayesian view. Consider the prior π(a)-1 for all a e R Consider a Gaussian linear model Y = aX+ E Determine whether each of the following statements is true or false. π(a) a uniform prior. (1) (a) True (b) False L(Y=y14=a,X=x) (2) π(a) is a jeffreys prior when we consider the likelihood (where we assume xis known) (a) True (b)False Y-XB+ σε where ε E R" is a random vector with Consider a linear regression model E[ε1-0, E[eErJ-1....
in a Bayesian view. Consider the prior π(a)-1 for all a e R Consider a Gaussian linear model Y = aX+ E Determine whether each of the following statements is true or false. π(a) a uniform prior. (1) (a) True (b) False L(Y=y14=a,X=x) (2) π(a) is a jeffreys prior when we consider the likelihood (where we assume xis known) (a) True (b)False Y-XB+ σε where ε E R" is a random vector with Consider a linear regression model E[ε1-0, E[eErJ-1....
Bookmark this page Setup: All problems on this page will follow the definitions here: Let X,...
 Bookmark this page Setup: All problems on this page will follow the definitions here: Let X, Y be two Bernoulli random variables and let P a r = = = P(X = 1) (the probability that X = 1) P(Y = 1) (the probability that Y = 1) P(X = 1, Y = 1) (the probability that both X = 1 and Y = 1). Let (X1,Y1), ... ,(Xn, Yn) be a sample of n i.i.d. copies of (X, Y)....
Bookmark this page Setup: All problems on this page will follow the definitions here: Let X, Y be two Bernoulli random variables and let P a r = = = P(X = 1) (the probability that X = 1) P(Y = 1) (the probability that Y = 1) P(X = 1, Y = 1) (the probability that both X = 1 and Y = 1). Let (X1,Y1), ... ,(Xn, Yn) be a sample of n i.i.d. copies of (X, Y)....
As on the previous page, let Xi,...,Xn be i.i.d. with pdf where >0 2 points possible...
 As on the previous page, let Xi,...,Xn be i.i.d. with pdf where >0 2 points possible (graded, results hidden) Assume we do not actually get to observe X, . . . , Xn. to estimate based on this new data. Instead let Yİ , . . . , Y, be our observations where Yi-l (X·S 0.5) . our goals What distribution does Yi follow? First, choose the type of the distribution: Bernoulli Poisson Norma Exponential Second, enter the parameter of...
As on the previous page, let Xi,...,Xn be i.i.d. with pdf where >0 2 points possible (graded, results hidden) Assume we do not actually get to observe X, . . . , Xn. to estimate based on this new data. Instead let Yİ , . . . , Y, be our observations where Yi-l (X·S 0.5) . our goals What distribution does Yi follow? First, choose the type of the distribution: Bernoulli Poisson Norma Exponential Second, enter the parameter of...
 Problem 4 True or False A Bookmark this page Instructions: Be very careful with the multiple choice questions below. Some are "choose all that apply," and many tests your knowledge of when particular statements apply As in the rest of this exam, only your last submission will count. 1 point possible (graded, results hidden) The likelihood ratio test is used to obtain a test with non-asymptotic level o True O False Submit You have used 0 of 3 attempts Save...
Problem 4 True or False A Bookmark this page Instructions: Be very careful with the multiple choice questions below. Some are "choose all that apply," and many tests your knowledge of when particular statements apply As in the rest of this exam, only your last submission will count. 1 point possible (graded, results hidden) The likelihood ratio test is used to obtain a test with non-asymptotic level o True O False Submit You have used 0 of 3 attempts Save...
 4.
Setup:
Suppose you have observations X1,X2,X3,X4,X5 which are i.i.d.
draws from a Gaussian distribution with unknown mean μ and unknown
variance σ2.
Given Facts:
You are given the following:
15∑i=15Xi=0.90,15∑i=15X2i=1.31
Bookmark this page Setup: Suppose you have observations X1, X2, X3, X4, X5 which are i.i.d. draws from a Gaussian distribution with unknown mean u and unknown variance o? Given Facts: You are given the following: x=030, =1:1 Choose a test 1 point possible (graded, results hidden) To test...
4.
Setup:
Suppose you have observations X1,X2,X3,X4,X5 which are i.i.d.
draws from a Gaussian distribution with unknown mean μ and unknown
variance σ2.
Given Facts:
You are given the following:
15∑i=15Xi=0.90,15∑i=15X2i=1.31
Bookmark this page Setup: Suppose you have observations X1, X2, X3, X4, X5 which are i.i.d. draws from a Gaussian distribution with unknown mean u and unknown variance o? Given Facts: You are given the following: x=030, =1:1 Choose a test 1 point possible (graded, results hidden) To test...
 1 Bookmark this page Setup: For all problems on this page, suppose you have data X],...,x . N (0,1) that is a random sample of identically and independently distributed standard normal random variables. Useful facts: The following facts might be useful: For a standard normal random variable X1, we have: E[X] =0, E[X{1=1, E(X) = 3. Sample mean 1.5 points possible (graded, results hidden) Consider the sample mean: X = x + X2+...+X,). What are the mean E [Xn] and...
1 Bookmark this page Setup: For all problems on this page, suppose you have data X],...,x . N (0,1) that is a random sample of identically and independently distributed standard normal random variables. Useful facts: The following facts might be useful: For a standard normal random variable X1, we have: E[X] =0, E[X{1=1, E(X) = 3. Sample mean 1.5 points possible (graded, results hidden) Consider the sample mean: X = x + X2+...+X,). What are the mean E [Xn] and...
 1. Implicit hypothesis testing Homework due Jul 29, 2020 07:59 HKT Bookmark this page Given n i.i.d. samples X1,..., X, N (u,02) with p ER and op > 0, we want to find a test with asymptotic level 5% for the hypotheses (7.1) Η :μοσ vs H, :μ<σ. (a) 1 point possible (graded) As a first step, define the maximum likelihood estimators ů = Xn, 32 = (X: – 8.)? Give a function g(x,y) such that P 9(î, o?) -0....
1. Implicit hypothesis testing Homework due Jul 29, 2020 07:59 HKT Bookmark this page Given n i.i.d. samples X1,..., X, N (u,02) with p ER and op > 0, we want to find a test with asymptotic level 5% for the hypotheses (7.1) Η :μοσ vs H, :μ<σ. (a) 1 point possible (graded) As a first step, define the maximum likelihood estimators ů = Xn, 32 = (X: – 8.)? Give a function g(x,y) such that P 9(î, o?) -0....
 Consider the training examples shown in the table below for a binary classification problem. (a) What is the entropy of this collection of training examples with respect to the positive class? (b) What are the information gains of a1 and a2 relative to these training examples? (c) For a3, which is a continuous attribute, compute the information gain for every possible split. (d) What is the best split (among a1 a2, and a3) according to the information gain? (e) What...
Consider the training examples shown in the table below for a binary classification problem. (a) What is the entropy of this collection of training examples with respect to the positive class? (b) What are the information gains of a1 and a2 relative to these training examples? (c) For a3, which is a continuous attribute, compute the information gain for every possible split. (d) What is the best split (among a1 a2, and a3) according to the information gain? (e) What...
 2. Biased and unbiased estimation for variance of Bernoulli variables A Bookmark this page 2 points possible (graded) Let X1, X, bed. Bernoull random variables, with unknown parameter PE (0,1). The aim of this exercise is to estimate the common variance of the X First, recall what Var (X) is for Bernoulli random variables. Var (X) - Let X, be the sample average of the Xi. X. - 3x Interested in finding an estimator for Var(X), and propose to use...
2. Biased and unbiased estimation for variance of Bernoulli variables A Bookmark this page 2 points possible (graded) Let X1, X, bed. Bernoull random variables, with unknown parameter PE (0,1). The aim of this exercise is to estimate the common variance of the X First, recall what Var (X) is for Bernoulli random variables. Var (X) - Let X, be the sample average of the Xi. X. - 3x Interested in finding an estimator for Var(X), and propose to use...
 8. Exercise: Counting committees Bookmark this page Exercise: Counting committees 0.0/2.0 points (graded) We start with a pool of n people. A chaired committee consists of k 1 members, out of whom one member is designated as the chairperson. The expression k(can be interpreted as the number of possible chaired committees with k members. This is because we have choices for the k members, and once the members are chosen, there are then k choices for the chairperson. Thus, is...
8. Exercise: Counting committees Bookmark this page Exercise: Counting committees 0.0/2.0 points (graded) We start with a pool of n people. A chaired committee consists of k 1 members, out of whom one member is designated as the chairperson. The expression k(can be interpreted as the number of possible chaired committees with k members. This is because we have choices for the k members, and once the members are chosen, there are then k choices for the chairperson. Thus, is...
 in a Bayesian view. Consider the prior π(a)-1 for all a e R Consider a Gaussian linear model Y = aX+ E Determine whether each of the following statements is true or false. π(a) a uniform prior. (1) (a) True (b) False L(Y=y14=a,X=x) (2) π(a) is a jeffreys prior when we consider the likelihood (where we assume xis known) (a) True (b)False Y-XB+ σε where ε E R" is a random vector with Consider a linear regression model E[ε1-0, E[eErJ-1....
in a Bayesian view. Consider the prior π(a)-1 for all a e R Consider a Gaussian linear model Y = aX+ E Determine whether each of the following statements is true or false. π(a) a uniform prior. (1) (a) True (b) False L(Y=y14=a,X=x) (2) π(a) is a jeffreys prior when we consider the likelihood (where we assume xis known) (a) True (b)False Y-XB+ σε where ε E R" is a random vector with Consider a linear regression model E[ε1-0, E[eErJ-1....
 Bookmark this page Setup: All problems on this page will follow the definitions here: Let X, Y be two Bernoulli random variables and let P a r = = = P(X = 1) (the probability that X = 1) P(Y = 1) (the probability that Y = 1) P(X = 1, Y = 1) (the probability that both X = 1 and Y = 1). Let (X1,Y1), ... ,(Xn, Yn) be a sample of n i.i.d. copies of (X, Y)....
Bookmark this page Setup: All problems on this page will follow the definitions here: Let X, Y be two Bernoulli random variables and let P a r = = = P(X = 1) (the probability that X = 1) P(Y = 1) (the probability that Y = 1) P(X = 1, Y = 1) (the probability that both X = 1 and Y = 1). Let (X1,Y1), ... ,(Xn, Yn) be a sample of n i.i.d. copies of (X, Y)....
 As on the previous page, let Xi,...,Xn be i.i.d. with pdf where >0 2 points possible (graded, results hidden) Assume we do not actually get to observe X, . . . , Xn. to estimate based on this new data. Instead let Yİ , . . . , Y, be our observations where Yi-l (X·S 0.5) . our goals What distribution does Yi follow? First, choose the type of the distribution: Bernoulli Poisson Norma Exponential Second, enter the parameter of...
As on the previous page, let Xi,...,Xn be i.i.d. with pdf where >0 2 points possible (graded, results hidden) Assume we do not actually get to observe X, . . . , Xn. to estimate based on this new data. Instead let Yİ , . . . , Y, be our observations where Yi-l (X·S 0.5) . our goals What distribution does Yi follow? First, choose the type of the distribution: Bernoulli Poisson Norma Exponential Second, enter the parameter of...
Most questions answered within 3 hours.
-
The Baily Corporation has developed a specialized software
program that improves inventory control capability. The following...
asked 1 minute ago -
Problem 5-4A (Part Level Submission) Wolford Department Store is
located in midtown Metropolis. During the past...
asked 1 minute ago -
Preparation of Benzoic Acid using a Grignard Reagent URGENT
1. During your Grignard formation, a small...
asked 24 minutes ago -
A uniform magnetic field is perpendicular to the plane of a wire
loop. If the loop...
asked 23 minutes ago -
At the peak of your career, your were earning $120,000 and
holding a top level position....
asked 26 minutes ago -
. A permanent magnet is dropped south-end-down through a horizontal
circular coil with a radius of...
asked 28 minutes ago -
Bernie's Beverages purchased some fixed assets classified as
5-year property for MACRS. The assets cost $28,000....
asked 42 minutes ago -
How many ATPs are produced from the catabolism of a 10-C
molecule of fatty acid under...
asked 47 minutes ago -
Before practicing a routine on the rings, a 64.8 kg gymnast
hangs motionless, with one hand...
asked 48 minutes ago -
If the K b of a weak base is 6.3 × 10 − 6 , what...
asked 55 minutes ago -
Which of the following is the minimum amount of moles of NaOH
that must be added...
asked 58 minutes ago -
Stories about organizational ________ provide important clues
about cultural values and norms.
a. myths
b. heroes...
asked 1 hour ago