
Homework Answers
a) The error (or disturbance) of an observed value is the deviation of the observed value from the (unobservable) true value of a quantity of interest (for example, a population mean), and the residual of an observed value is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean).
b) Residual is also a type of error but stochastic error is the difference of the observed from the true value whereas residual is from estimated value
c) The error term is the difference between the observed value
for the dependent variable and its theoretical value, while a model
is applied on overall population. We don't actually calculate
it.
Residual is the practically calculated term during modeling
exercise; It is the difference between the actual value in the
sample and predicated value in the sample.
d)
In econometric theory, the classical normal linear regression model (CNLRM) involves finding the best fitting linear model for observed data that shows the relationship between two variables.
For example, let’s say you were running a study on the way the number of exams in a certain college affect the amount of red bull purchased from college vending machines. You could collect data which told you how many exams were given and how much red bull was purchased on a dozen or more days during the semester. This data can be plotted as a scatter plot, with exams (Ex) per given day on the x axis and red bull purchased (RB) per given day on the y axis. Then you would look for the line y = β0 + β1 x that best fit the data.
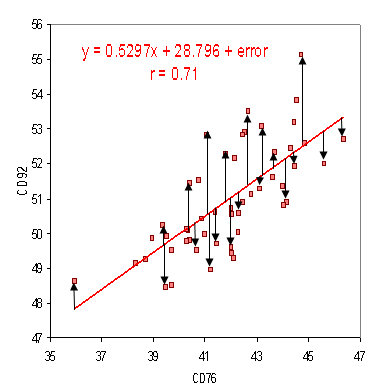
Errors on a scatter plot.
“Best fit” here means that the error term, the distance from each point to the line, is minimized. Since the relationship between variables is probably not completely linear and because there are other factors outside the scope of our study (sales on red bull, sales on other caffeine drinks, difficult physics homework sets, etc.) the graph won’t actually go through all our data points. The distance between each point and the linear graph (shown as black arrows on the above graph) is our error term. So we can write our function as RB=β0 + β1 Ex + ε where β0 and β1 are constants and ε is an (non constant) error term.
e)
Suppose that we are given the following set of paired data:
(1, 2), (2, 3), (3, 7), (3, 6), (4, 9), (5, 9)
By using software we can see that the least squares regression line is y = 2x. We will use this to predict values for each value of x.
For example, when x = 5 we see that 2(5) = 10. This gives us the point along our regression line that has an x coordinate of 5.
To calculate the residual at the points x = 5, we subtract the predicted value from our observed value. Since the y coordinate of our data point was 9, this gives a residual of 9 – 10 = -1.
In the following table we see how to calculate all of our residuals for this data set:
| X | Observed y | Predicted y | Residual |
| 1 | 2 | 2 | 0 |
| 2 | 3 | 4 | -1 |
| 3 | 7 | 6 | 1 |
| 3 | 6 | 6 | 0 |
| 4 | 9 | 8 | 1 |
| 5 | 9 | 10 | -1 |
Add Answer to:
Econometrics Midterm Exam First Name: uskals Last Name: Sunculk ReddySIN: Grade: Two of the most important...
4. Question 4: Consider the following equation for U.S. per capita consumption of beef: CB--330.3+ 49.1InY,...
 4. Question 4: Consider the following equation for U.S. per capita consumption of beef: CB--330.3+ 49.1InY, 0.34 PB,+0.33 PRP 15.4 D (se 7.4 t-6.6) (se-0.13 -2.6) (se-0.12 t-2.7) (se-4.1 -3.7) RP = 0.7 N 28 DW = 0.94 where CB. the annual per capita pounds of beef consumed in the U.S. in year t, In Yǐ : the log of per capita disposable real income in the U.S. in year t, PBt Ξ , PRI average annualized real wholesale price...
4. Question 4: Consider the following equation for U.S. per capita consumption of beef: CB--330.3+ 49.1InY, 0.34 PB,+0.33 PRP 15.4 D (se 7.4 t-6.6) (se-0.13 -2.6) (se-0.12 t-2.7) (se-4.1 -3.7) RP = 0.7 N 28 DW = 0.94 where CB. the annual per capita pounds of beef consumed in the U.S. in year t, In Yǐ : the log of per capita disposable real income in the U.S. in year t, PBt Ξ , PRI average annualized real wholesale price...
Huang and others (1980) estimated the following demand for coffee: h 0,-1.279-0.1647h P+0.5115n ,0.1483h P-0.00897 -0.096D,-0.157D, +0.0097D, (-2.14) .23) (0.55) 3.36) (-3.34) (-6.03) (-0.37)...
 Huang and others (1980) estimated the following demand for coffee: h 0,-1.279-0.1647h P+0.5115n ,0.1483h P-0.00897 -0.096D,-0.157D, +0.0097D, (-2.14) .23) (0.55) 3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices Per capita income in thousands of 1967 dollars P': Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter Ds Dummy variable...
Huang and others (1980) estimated the following demand for coffee: h 0,-1.279-0.1647h P+0.5115n ,0.1483h P-0.00897 -0.096D,-0.157D, +0.0097D, (-2.14) .23) (0.55) 3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices Per capita income in thousands of 1967 dollars P': Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter Ds Dummy variable...
2. Huang and others (1980) estimated the following demand for coffee: In 0, -1.279-0.1647h P+0.5115h I, +0.1483n P,-0.0089T, -0.096D,-0.157D, +0.0097D, (-2.14) (1.23) (0.55) (3.36) (-3.34) (-6.0...
 2. Huang and others (1980) estimated the following demand for coffee: In 0, -1.279-0.1647h P+0.5115h I, +0.1483n P,-0.0089T, -0.096D,-0.157D, +0.0097D, (-2.14) (1.23) (0.55) (3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices IPer capita income in thousands of 1967 dollars P' Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter...
2. Huang and others (1980) estimated the following demand for coffee: In 0, -1.279-0.1647h P+0.5115h I, +0.1483n P,-0.0089T, -0.096D,-0.157D, +0.0097D, (-2.14) (1.23) (0.55) (3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices IPer capita income in thousands of 1967 dollars P' Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter...
Ignore Number 6 5. A sample of 30 houses that were sold in the last year...
 Ignore Number 6
5. A sample of 30 houses that were sold in the last year was taken. The value of the house (y, in dollars) was estimated. The independent variables included in the analysis were the number of rooms (xi), the size of the lot (x2, in sq ft), the number of bathrooms (x3), and a dummy variable (x4), which equals 0 if the house does not have a garage and equals 1 otherwise. The following regression results were...
Ignore Number 6
5. A sample of 30 houses that were sold in the last year was taken. The value of the house (y, in dollars) was estimated. The independent variables included in the analysis were the number of rooms (xi), the size of the lot (x2, in sq ft), the number of bathrooms (x3), and a dummy variable (x4), which equals 0 if the house does not have a garage and equals 1 otherwise. The following regression results were...
QUESTION 34 We are analyzing the effects of regime type on corruption rates with the following...
QUESTION 34 We are analyzing the effects of regime type on corruption rates with the following model: Corruption = 10 - 0.1 GDP (per capita) - 2.0Democracy where Corruption is an index of corruption, GDP (per capita) is measured in thousands of dollars, and Democracy is a dummy variable that is equal to one if a country is a democracy and 0 otherwise. What is the expected rate of corruption of a democratic country with a per capita GDP of...
In a study of the long-run and short-run demands for money, Chow estimated the following demand...
In a study of the long-run and short-run demands for money, Chow estimated the following demand equation (standard errors in parentheses) for the United States from 1947:1 through 1965:4: Mt=0.14+1.05Yt*-0.01Yt-0.75Rt (0.15) (0.10) (0.05) R2= 0.996 DW = 0.88** Breusch-Godfrey LM Test= 8.38** N = 76 (quarterly) where: Mt = the log of the money stock in quarter t Yt* = the log of permanent income (a moving average of previous quarters’ current income) in quarter t Yt = the...
Where wage is in 1000's of dollars. Now suppose that your econometrics give you the to...
 Where wage is in 1000's of dollars. Now suppose that your econometrics give you the to Wage = Bo + Bi Education + e that your econometrics give you the following results: Constant Education Coefficient 45.32 10.32 5 Standard Error 30.65 2.35 N=42 a. Estimate a 95% confidence interval for a 95% confidence interval for B.. Show your work carefully. What does this ence interval tell us about the relationship between education and wages? (2 marks) b. Test at the...
Where wage is in 1000's of dollars. Now suppose that your econometrics give you the to Wage = Bo + Bi Education + e that your econometrics give you the following results: Constant Education Coefficient 45.32 10.32 5 Standard Error 30.65 2.35 N=42 a. Estimate a 95% confidence interval for a 95% confidence interval for B.. Show your work carefully. What does this ence interval tell us about the relationship between education and wages? (2 marks) b. Test at the...
Thomas Bruggink and David Rose' estimated a regression for the annual team revenue for Major League...
 Thomas Bruggink and David Rose' estimated a regression for the annual team revenue for Major League Baseball franchises (standard errors in parenthesis): Ri= –1522.5 +53.1P: + 1469.4M + 1322.75 — 7376.31 (9.1) (233.6) (1363.6) (2255.7) R2= .682 N = 78 where: R = team revenue from attendance, broadcasting, and concessions (in $000's) P. = the ith team's winning rate (times 1,000) M = the population of the ith team's metropolitan area (in millions) S = a dummy equal to 1...
Thomas Bruggink and David Rose' estimated a regression for the annual team revenue for Major League Baseball franchises (standard errors in parenthesis): Ri= –1522.5 +53.1P: + 1469.4M + 1322.75 — 7376.31 (9.1) (233.6) (1363.6) (2255.7) R2= .682 N = 78 where: R = team revenue from attendance, broadcasting, and concessions (in $000's) P. = the ith team's winning rate (times 1,000) M = the population of the ith team's metropolitan area (in millions) S = a dummy equal to 1...
gretl: model 1 File Edit Tests Save Graphs Analysis LaTeX Question 5 In your first year...
 gretl: model 1 File Edit Tests Save Graphs Analysis LaTeX Question 5 In your first year microeconomics course you learned about differentiated products. As an econometrics student differentiated products are interesting because they are prime candidates for hedonic price modelling. As mentioned in class, a hedonic price model is a regression model that relates the price of a differentiated product (a residential house in this case) to its characteristics. For this assignment you will construct a simple hedonic model for...
gretl: model 1 File Edit Tests Save Graphs Analysis LaTeX Question 5 In your first year microeconomics course you learned about differentiated products. As an econometrics student differentiated products are interesting because they are prime candidates for hedonic price modelling. As mentioned in class, a hedonic price model is a regression model that relates the price of a differentiated product (a residential house in this case) to its characteristics. For this assignment you will construct a simple hedonic model for...
Simple Linear regression 1. A researcher uses a simple linear regression to measure the relationship between...
 Simple Linear regression
1. A researcher uses a simple linear regression to measure the relationship between the monthly salary (Salary measured in dollars) of data scientists and the number of years since being awarded a Master degree (Master Degree). A random sample of 80 observations was collected for the analysis. A researcher used the econometric model which has the following specification Salary,-β0 + β, Master-Degree, + εί, where i = 1, , 80 The (incomplete) Excel output of equation (1)...
Simple Linear regression
1. A researcher uses a simple linear regression to measure the relationship between the monthly salary (Salary measured in dollars) of data scientists and the number of years since being awarded a Master degree (Master Degree). A random sample of 80 observations was collected for the analysis. A researcher used the econometric model which has the following specification Salary,-β0 + β, Master-Degree, + εί, where i = 1, , 80 The (incomplete) Excel output of equation (1)...
 4. Question 4: Consider the following equation for U.S. per capita consumption of beef: CB--330.3+ 49.1InY, 0.34 PB,+0.33 PRP 15.4 D (se 7.4 t-6.6) (se-0.13 -2.6) (se-0.12 t-2.7) (se-4.1 -3.7) RP = 0.7 N 28 DW = 0.94 where CB. the annual per capita pounds of beef consumed in the U.S. in year t, In Yǐ : the log of per capita disposable real income in the U.S. in year t, PBt Ξ , PRI average annualized real wholesale price...
4. Question 4: Consider the following equation for U.S. per capita consumption of beef: CB--330.3+ 49.1InY, 0.34 PB,+0.33 PRP 15.4 D (se 7.4 t-6.6) (se-0.13 -2.6) (se-0.12 t-2.7) (se-4.1 -3.7) RP = 0.7 N 28 DW = 0.94 where CB. the annual per capita pounds of beef consumed in the U.S. in year t, In Yǐ : the log of per capita disposable real income in the U.S. in year t, PBt Ξ , PRI average annualized real wholesale price...
 Huang and others (1980) estimated the following demand for coffee: h 0,-1.279-0.1647h P+0.5115n ,0.1483h P-0.00897 -0.096D,-0.157D, +0.0097D, (-2.14) .23) (0.55) 3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices Per capita income in thousands of 1967 dollars P': Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter Ds Dummy variable...
Huang and others (1980) estimated the following demand for coffee: h 0,-1.279-0.1647h P+0.5115n ,0.1483h P-0.00897 -0.096D,-0.157D, +0.0097D, (-2.14) .23) (0.55) 3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices Per capita income in thousands of 1967 dollars P': Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter Ds Dummy variable...
 2. Huang and others (1980) estimated the following demand for coffee: In 0, -1.279-0.1647h P+0.5115h I, +0.1483n P,-0.0089T, -0.096D,-0.157D, +0.0097D, (-2.14) (1.23) (0.55) (3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices IPer capita income in thousands of 1967 dollars P' Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter...
2. Huang and others (1980) estimated the following demand for coffee: In 0, -1.279-0.1647h P+0.5115h I, +0.1483n P,-0.0089T, -0.096D,-0.157D, +0.0097D, (-2.14) (1.23) (0.55) (3.36) (-3.34) (-6.03) (-0.37) Where: Q- pounds of coffee P price of coffee per pound in 1967 prices IPer capita income in thousands of 1967 dollars P' Price of tea in 1967 prices T time variable 1961-quarter 1 through 1977-quarter 4 D1 Dummy variable -1 for the first quarter D2- Dummy variable -1 for the second quarter...
 Ignore Number 6
5. A sample of 30 houses that were sold in the last year was taken. The value of the house (y, in dollars) was estimated. The independent variables included in the analysis were the number of rooms (xi), the size of the lot (x2, in sq ft), the number of bathrooms (x3), and a dummy variable (x4), which equals 0 if the house does not have a garage and equals 1 otherwise. The following regression results were...
Ignore Number 6
5. A sample of 30 houses that were sold in the last year was taken. The value of the house (y, in dollars) was estimated. The independent variables included in the analysis were the number of rooms (xi), the size of the lot (x2, in sq ft), the number of bathrooms (x3), and a dummy variable (x4), which equals 0 if the house does not have a garage and equals 1 otherwise. The following regression results were...
 Where wage is in 1000's of dollars. Now suppose that your econometrics give you the to Wage = Bo + Bi Education + e that your econometrics give you the following results: Constant Education Coefficient 45.32 10.32 5 Standard Error 30.65 2.35 N=42 a. Estimate a 95% confidence interval for a 95% confidence interval for B.. Show your work carefully. What does this ence interval tell us about the relationship between education and wages? (2 marks) b. Test at the...
Where wage is in 1000's of dollars. Now suppose that your econometrics give you the to Wage = Bo + Bi Education + e that your econometrics give you the following results: Constant Education Coefficient 45.32 10.32 5 Standard Error 30.65 2.35 N=42 a. Estimate a 95% confidence interval for a 95% confidence interval for B.. Show your work carefully. What does this ence interval tell us about the relationship between education and wages? (2 marks) b. Test at the...
 Thomas Bruggink and David Rose' estimated a regression for the annual team revenue for Major League Baseball franchises (standard errors in parenthesis): Ri= –1522.5 +53.1P: + 1469.4M + 1322.75 — 7376.31 (9.1) (233.6) (1363.6) (2255.7) R2= .682 N = 78 where: R = team revenue from attendance, broadcasting, and concessions (in $000's) P. = the ith team's winning rate (times 1,000) M = the population of the ith team's metropolitan area (in millions) S = a dummy equal to 1...
Thomas Bruggink and David Rose' estimated a regression for the annual team revenue for Major League Baseball franchises (standard errors in parenthesis): Ri= –1522.5 +53.1P: + 1469.4M + 1322.75 — 7376.31 (9.1) (233.6) (1363.6) (2255.7) R2= .682 N = 78 where: R = team revenue from attendance, broadcasting, and concessions (in $000's) P. = the ith team's winning rate (times 1,000) M = the population of the ith team's metropolitan area (in millions) S = a dummy equal to 1...
 gretl: model 1 File Edit Tests Save Graphs Analysis LaTeX Question 5 In your first year microeconomics course you learned about differentiated products. As an econometrics student differentiated products are interesting because they are prime candidates for hedonic price modelling. As mentioned in class, a hedonic price model is a regression model that relates the price of a differentiated product (a residential house in this case) to its characteristics. For this assignment you will construct a simple hedonic model for...
gretl: model 1 File Edit Tests Save Graphs Analysis LaTeX Question 5 In your first year microeconomics course you learned about differentiated products. As an econometrics student differentiated products are interesting because they are prime candidates for hedonic price modelling. As mentioned in class, a hedonic price model is a regression model that relates the price of a differentiated product (a residential house in this case) to its characteristics. For this assignment you will construct a simple hedonic model for...
 Simple Linear regression
1. A researcher uses a simple linear regression to measure the relationship between the monthly salary (Salary measured in dollars) of data scientists and the number of years since being awarded a Master degree (Master Degree). A random sample of 80 observations was collected for the analysis. A researcher used the econometric model which has the following specification Salary,-β0 + β, Master-Degree, + εί, where i = 1, , 80 The (incomplete) Excel output of equation (1)...
Simple Linear regression
1. A researcher uses a simple linear regression to measure the relationship between the monthly salary (Salary measured in dollars) of data scientists and the number of years since being awarded a Master degree (Master Degree). A random sample of 80 observations was collected for the analysis. A researcher used the econometric model which has the following specification Salary,-β0 + β, Master-Degree, + εί, where i = 1, , 80 The (incomplete) Excel output of equation (1)...
Most questions answered within 3 hours.
-
A college student is employed as a door-to-door newspaper
salesman. Historical data suggests that the student...
asked 41 minutes ago -
MATLAB HW 11 problem using Switch Case and Input commands
Write a script file that calculates...
asked 26 minutes ago -
Considering gravitational time dilation, calculate the time that
passes in Earth’s surface while 1 hour passes...
asked 1 hour ago -
Minitab Problem: Take the Lake Hume June rainfall data and find
use the processes outlined in...
asked 1 hour ago -
X Company is trying to decide whether to continue using old
equipment to make Product A...
asked 1 hour ago -
IN PYTHON ONLY !! Program 2: Re-work
program #5 (WeeklyHours) from the previous assignment such that...
asked 2 hours ago -
The average length of time between arrivals at a turnpike
toll-booth is 26 seconds. What is...
asked 4 hours ago -
(a) A piston at 6.1 atm contains a gas that occupies a volume of
3.5 L....
asked 5 hours ago -
Please answer true or false. Words
cannot be changed or added in to make it true...
asked 5 hours ago -
An empty test tube weighs 15.923 grams. Then,
MgCl2•6H2O is added into the test tube. After...
asked 5 hours ago -
Assume memory access is 10 units of time and disk access is
10000 units of time....
asked 5 hours ago -
1. Are all good samples random?
2. Magazines often report surveys giving statistics such as “63%...
asked 6 hours ago