Please answer this question with RStudio.

Homework Answers
R code with comments (all statements starting with # are comments)
#set the parameters of gamma distribution
k<-2
theta<-3
#part a)
#set the values of x
x<-seq(0,20,length=100)
#get the density of x
p<-dgamma(x,shape=k,scale=theta)
#plot
plot(x,p,type="l",ylab="density",main=bquote("Density of gamma
distribution with k=2,"*theta*"=3"))
#get this plot
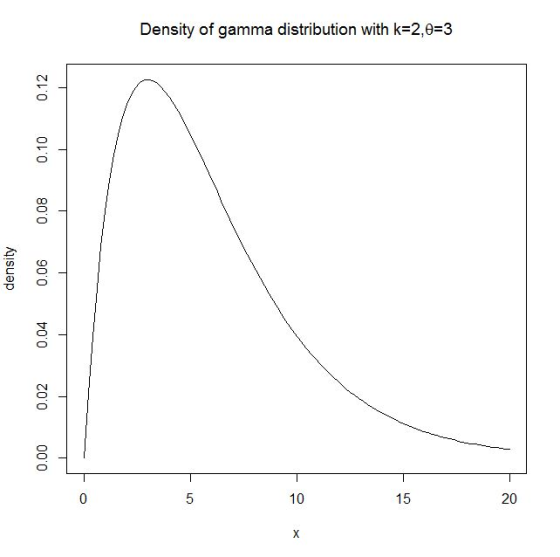
b) The expected value (true mean) of X is
the variance of X is
#part b)
#expected value is
mu<-k*theta
sigma2<-k*theta^2
sprintf('The true mean of X is %.4f',mu)
sprintf('The true variance of X is %.4f',sigma2)
#get this poutput
![> 3printf (The true mean of X 13·4f,mu) [1] The true mean of X is 6.0000 > sprintf (The true variance f X is % .4 f, sigma2 ) [1] The true variance of X is 18.0000](http://img.homeworklib.com/questions/6ca650e0-70f2-11ea-a2aa-31c6eecee237.png?x-oss-process=image/resize,w_560)
c) Each sample of size 12 is a draw from Gamma distribution and they are different.
Since s are random
variables, the sum
is also a random variable.
If we divide this sum by n, the average that we get of these
s
is also random.
Hence
is a random variable.
d) the true mean of is
The true variance of is
The true standard deviation of is
R code
#part d)
#set the sample size
n<-12
#get the true mean of sample mean
muxbar<-mu
#get the true variance of sample mean
sigma2xbar<-sigma2/n
#get the true standard deviation of sample mean
sigmaxbar<-sqrt(sigma2xbar)
sprintf('The true mean of sample mean is %.4f',muxbar)
sprintf('The true variance of sample mean is
%.4f',sigma2xbar)
sprintf('The true standard deviation of sample mean is
%.4f',sigmaxbar)
#get this output

e) R code
#part e)
#set the random seed
set.seed(123)
#set the sample size
n<-12
#set the number of repetition
r<-10000
#intialize the variable to store the z values
z<-numeric(r)
for (i in 1:r) {
x<-rgamma(n,shape=k,scale=theta)
#get the sample mean m
m<-mean(x)
#calculate the test statistics
z[i]<-(m-6)/sigmaxbar
}
#plot the histogram of z
hist(z,breaks=50,freq=FALSE,xlab="Test statistics
(z)",main="Histogram of the test statistics")
#add dnorm
curve(dnorm(x),from=min(z),to=max(z),add=TRUE,col="red")
#get this plot
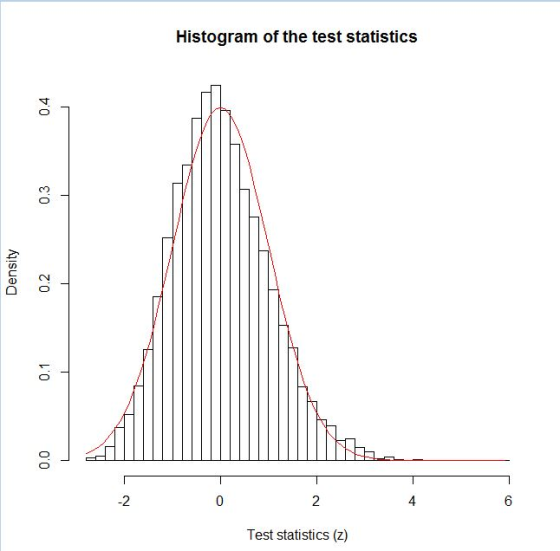
The distribution of the test statistics is reasonably well approximated by a normal distribution.
f) Using sample standard deviation
#part f)
#set the random seed
set.seed(123)
#set the sample size
n<-12
#set the number of repeatition
r<-10000
#intialize the variable to store the z values
t<-numeric(r)
for (i in 1:r) {
x<-rgamma(n,shape=k,scale=theta)
#get the sample mean m
m<-mean(x)
#get the sample standard deviation
s<-sd(x)
#calculate the test statistics
t[i]<-(m-6)/(s/sqrt(n))
}
#plot the histogram of t
hist(t,breaks=50,freq=FALSE,xlab="Test statistics
(t)",main="Histogram of the test statistics",ylim=c(0,0.4))
#add dnorm
curve(dnorm(x),from=min(t),to=max(t),add=TRUE,col="red")
#add dt
curve(dt(x,df=n-1),from=min(t),to=max(t),add=TRUE,col="blue")
legend("topleft",c("test statistics","standard normal","standard
t"),lty=1,col=c("black","red","blue"))
#get this plot
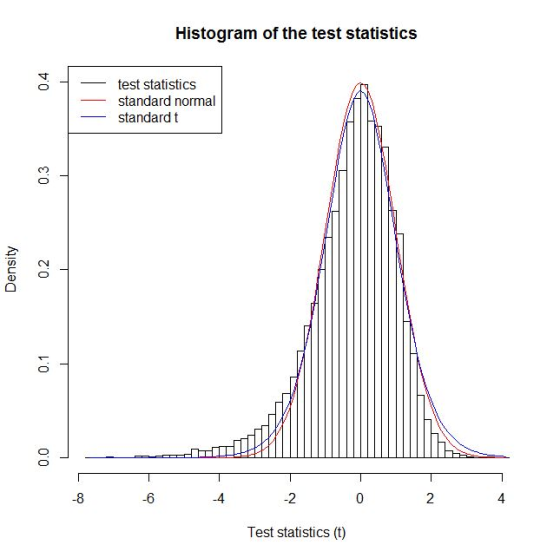
t distribution with its thicket tail seems to be a better fit than standard normal, particularly for the left tail.
Add Answer to:
Please answer this question with RStudio.
4. In this problem, you will illustrate the idea of...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indi...
 A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-60. Let μ denote the true average compressive strength (a) What are the appropriate null and alternative hypotheses? Ho: μ < 1300 Hai μ-1300 Hu: μ-1300...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-60. Let μ denote the true average compressive strength (a) What are the appropriate null and alternative hypotheses? Ho: μ < 1300 Hai μ-1300 Hu: μ-1300...
please answer correctly and answer all questions.. this is revision question... 7. Which of the following...
 please answer correctly and answer all questions.. this is
revision question...
7. Which of the following is BEST graphical method for describing categorical data? A. Bar chart B. Histogram C.Box-plot D. Pareto chart 8. Which of the following is NOT property of the variance? A. It measures the amount of spread or variability of observation from mean B. Standard deviation is square root of variance C. Normally used for describing measure of dispersion during reporting research data D. It is...
please answer correctly and answer all questions.. this is
revision question...
7. Which of the following is BEST graphical method for describing categorical data? A. Bar chart B. Histogram C.Box-plot D. Pareto chart 8. Which of the following is NOT property of the variance? A. It measures the amount of spread or variability of observation from mean B. Standard deviation is square root of variance C. Normally used for describing measure of dispersion during reporting research data D. It is...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have...
 A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-70. Let μ denote the true average compressive strength. a) What are the a null and altenative hypotheses? Ho: 1300 на: #1300 Ho:> 1300 hja: μ-1300...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-70. Let μ denote the true average compressive strength. a) What are the a null and altenative hypotheses? Ho: 1300 на: #1300 Ho:> 1300 hja: μ-1300...
3. Testing a population mean The test statistic (Chapter 11) Aa Aa You conduct a hypothesis...
 3. Testing a population mean The test statistic (Chapter 11) Aa Aa You conduct a hypothesis test about a population mean u with the following null and alternative hypotheses: Ho: u-25.8 H1: <25.8 Suppose that the population standard deviation has a known value of a observations, which provides a sample mean of % 30.7. 17.8. You obtain a sample of n =62 Since the sample size large enough, you assume that the sample mean X follows a normal distribution. Let...
3. Testing a population mean The test statistic (Chapter 11) Aa Aa You conduct a hypothesis test about a population mean u with the following null and alternative hypotheses: Ho: u-25.8 H1: <25.8 Suppose that the population standard deviation has a known value of a observations, which provides a sample mean of % 30.7. 17.8. You obtain a sample of n =62 Since the sample size large enough, you assume that the sample mean X follows a normal distribution. Let...
please answer correctly and answer all question.. this is revision question.. thanks.. 21. Which of the...
 please answer correctly and answer all question..
this is revision question.. thanks..
21. Which of the following is FALSE regarding ANOVA test? A. The Kruskal-Wallis test is the non-parametric equivalent for one-way ANOVA test B. The independent variable in one-way ANOVA test should be a categorical variable The dependent variable in one-way ANOVA test should be a numerical variable (D.Doe-way ANOVA test cannot be applied to compare two means (comparison of two groups) 22. Which of the following is FALSE...
please answer correctly and answer all question..
this is revision question.. thanks..
21. Which of the following is FALSE regarding ANOVA test? A. The Kruskal-Wallis test is the non-parametric equivalent for one-way ANOVA test B. The independent variable in one-way ANOVA test should be a categorical variable The dependent variable in one-way ANOVA test should be a numerical variable (D.Doe-way ANOVA test cannot be applied to compare two means (comparison of two groups) 22. Which of the following is FALSE...
Univariate Gaussians or normal distributions have a simple representation in that they can be completely described...
 Univariate Gaussians or normal distributions have a simple representation in that they can be completely described by their mean and variance. These distributions are particularly useful because of the central limit theorem, which posits that when a large number of independent random variables are added, the distribution of their sum is approximated by a normal distribution. In other words, normal distributions can be applied to most problems Recall the probability density function of the Univariate Gaussian with mean and variance...
Univariate Gaussians or normal distributions have a simple representation in that they can be completely described by their mean and variance. These distributions are particularly useful because of the central limit theorem, which posits that when a large number of independent random variables are added, the distribution of their sum is approximated by a normal distribution. In other words, normal distributions can be applied to most problems Recall the probability density function of the Univariate Gaussian with mean and variance...
Please answer both 1 & 2. 1. Use Excel to generate 100 observations from the standard...
Please answer both 1 & 2. 1. Use Excel to generate 100 observations from the standard Normal distribution. a.Make a histogram of these observations. How does the shape of this histogram compare with a Normal density curve? 2. Use Excel to generate 100 Normally distributed random values (that is 100 outcomes of a Normally distributed random variable with mean 10 and standard deviation of 5). a. Make a histogram for your data. How does the shape of this histogram compare...
Please use html format! II. The goal of this problem is to simulate the distribution of the sample mean. We will...
 Please use html format!
II. The goal of this problem is to simulate the distribution of the sample mean. We will use the buit load the dataset and avoid some problems, copy and paste the following command in dataset 1ynx. To lynx as.numeric(lynx) Assume this vector represents the population. Le, the mean of this vector is our "true mean" (a) Draw a histogram of the population, find the "true" mean, and the true" variance. Does this data look normally distributed?...
Please use html format!
II. The goal of this problem is to simulate the distribution of the sample mean. We will use the buit load the dataset and avoid some problems, copy and paste the following command in dataset 1ynx. To lynx as.numeric(lynx) Assume this vector represents the population. Le, the mean of this vector is our "true mean" (a) Draw a histogram of the population, find the "true" mean, and the true" variance. Does this data look normally distributed?...
R problem 1: The reason that the t distribution is important is that the sampling distribution...
 R problem 1: The reason that the t distribution is important is that the sampling distribution of the standardized sample mean is different depending on whether we use the true population standard deviation or one estimated from sample data. This problem addresses this issue. 1. Generate 10,000 samples of size n- 4 from a normal distribution with mean 100 and standard deviation σ = 12, Find the 10,000 sample means and find the 10,000 sample standard deviations. What are the...
R problem 1: The reason that the t distribution is important is that the sampling distribution of the standardized sample mean is different depending on whether we use the true population standard deviation or one estimated from sample data. This problem addresses this issue. 1. Generate 10,000 samples of size n- 4 from a normal distribution with mean 100 and standard deviation σ = 12, Find the 10,000 sample means and find the 10,000 sample standard deviations. What are the...
Software can generate samples from (almost) exactly Normal distributions. Here is a random sample of size...
 Software can generate samples from (almost) exactly Normal distributions. Here is a random sample of size 5 from the Normal distribution with mean 8 and standard deviation 2: 4.47 5.51 8.1 11.63 7.91 Although we know the true value of μ suppose we pretend that we do not and we test the hypotheses Ho : μ-5.6 a:μ 5.6 at the α 0.05 significance level. What is the power of the test against the alternative μ 8 (the actual population mean)?...
Software can generate samples from (almost) exactly Normal distributions. Here is a random sample of size 5 from the Normal distribution with mean 8 and standard deviation 2: 4.47 5.51 8.1 11.63 7.91 Although we know the true value of μ suppose we pretend that we do not and we test the hypotheses Ho : μ-5.6 a:μ 5.6 at the α 0.05 significance level. What is the power of the test against the alternative μ 8 (the actual population mean)?...
 A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-60. Let μ denote the true average compressive strength (a) What are the appropriate null and alternative hypotheses? Ho: μ < 1300 Hai μ-1300 Hu: μ-1300...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-60. Let μ denote the true average compressive strength (a) What are the appropriate null and alternative hypotheses? Ho: μ < 1300 Hai μ-1300 Hu: μ-1300...
 please answer correctly and answer all questions.. this is
revision question...
7. Which of the following is BEST graphical method for describing categorical data? A. Bar chart B. Histogram C.Box-plot D. Pareto chart 8. Which of the following is NOT property of the variance? A. It measures the amount of spread or variability of observation from mean B. Standard deviation is square root of variance C. Normally used for describing measure of dispersion during reporting research data D. It is...
please answer correctly and answer all questions.. this is
revision question...
7. Which of the following is BEST graphical method for describing categorical data? A. Bar chart B. Histogram C.Box-plot D. Pareto chart 8. Which of the following is NOT property of the variance? A. It measures the amount of spread or variability of observation from mean B. Standard deviation is square root of variance C. Normally used for describing measure of dispersion during reporting research data D. It is...
 A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-70. Let μ denote the true average compressive strength. a) What are the a null and altenative hypotheses? Ho: 1300 на: #1300 Ho:> 1300 hja: μ-1300...
A mixture of pulverized fuel ash and Portland cement to be used for grouting should have a compressive strength of more than 1300 KN/m2. The mixture will not be used unless experimental evidence indicates conclusively that the strength specification has been met. Suppose compressive strength for specimens of this mixture is normally distributed with σ-70. Let μ denote the true average compressive strength. a) What are the a null and altenative hypotheses? Ho: 1300 на: #1300 Ho:> 1300 hja: μ-1300...
 3. Testing a population mean The test statistic (Chapter 11) Aa Aa You conduct a hypothesis test about a population mean u with the following null and alternative hypotheses: Ho: u-25.8 H1: <25.8 Suppose that the population standard deviation has a known value of a observations, which provides a sample mean of % 30.7. 17.8. You obtain a sample of n =62 Since the sample size large enough, you assume that the sample mean X follows a normal distribution. Let...
3. Testing a population mean The test statistic (Chapter 11) Aa Aa You conduct a hypothesis test about a population mean u with the following null and alternative hypotheses: Ho: u-25.8 H1: <25.8 Suppose that the population standard deviation has a known value of a observations, which provides a sample mean of % 30.7. 17.8. You obtain a sample of n =62 Since the sample size large enough, you assume that the sample mean X follows a normal distribution. Let...
 please answer correctly and answer all question..
this is revision question.. thanks..
21. Which of the following is FALSE regarding ANOVA test? A. The Kruskal-Wallis test is the non-parametric equivalent for one-way ANOVA test B. The independent variable in one-way ANOVA test should be a categorical variable The dependent variable in one-way ANOVA test should be a numerical variable (D.Doe-way ANOVA test cannot be applied to compare two means (comparison of two groups) 22. Which of the following is FALSE...
please answer correctly and answer all question..
this is revision question.. thanks..
21. Which of the following is FALSE regarding ANOVA test? A. The Kruskal-Wallis test is the non-parametric equivalent for one-way ANOVA test B. The independent variable in one-way ANOVA test should be a categorical variable The dependent variable in one-way ANOVA test should be a numerical variable (D.Doe-way ANOVA test cannot be applied to compare two means (comparison of two groups) 22. Which of the following is FALSE...
 Univariate Gaussians or normal distributions have a simple representation in that they can be completely described by their mean and variance. These distributions are particularly useful because of the central limit theorem, which posits that when a large number of independent random variables are added, the distribution of their sum is approximated by a normal distribution. In other words, normal distributions can be applied to most problems Recall the probability density function of the Univariate Gaussian with mean and variance...
Univariate Gaussians or normal distributions have a simple representation in that they can be completely described by their mean and variance. These distributions are particularly useful because of the central limit theorem, which posits that when a large number of independent random variables are added, the distribution of their sum is approximated by a normal distribution. In other words, normal distributions can be applied to most problems Recall the probability density function of the Univariate Gaussian with mean and variance...
 Please use html format!
II. The goal of this problem is to simulate the distribution of the sample mean. We will use the buit load the dataset and avoid some problems, copy and paste the following command in dataset 1ynx. To lynx as.numeric(lynx) Assume this vector represents the population. Le, the mean of this vector is our "true mean" (a) Draw a histogram of the population, find the "true" mean, and the true" variance. Does this data look normally distributed?...
Please use html format!
II. The goal of this problem is to simulate the distribution of the sample mean. We will use the buit load the dataset and avoid some problems, copy and paste the following command in dataset 1ynx. To lynx as.numeric(lynx) Assume this vector represents the population. Le, the mean of this vector is our "true mean" (a) Draw a histogram of the population, find the "true" mean, and the true" variance. Does this data look normally distributed?...
 R problem 1: The reason that the t distribution is important is that the sampling distribution of the standardized sample mean is different depending on whether we use the true population standard deviation or one estimated from sample data. This problem addresses this issue. 1. Generate 10,000 samples of size n- 4 from a normal distribution with mean 100 and standard deviation σ = 12, Find the 10,000 sample means and find the 10,000 sample standard deviations. What are the...
R problem 1: The reason that the t distribution is important is that the sampling distribution of the standardized sample mean is different depending on whether we use the true population standard deviation or one estimated from sample data. This problem addresses this issue. 1. Generate 10,000 samples of size n- 4 from a normal distribution with mean 100 and standard deviation σ = 12, Find the 10,000 sample means and find the 10,000 sample standard deviations. What are the...
 Software can generate samples from (almost) exactly Normal distributions. Here is a random sample of size 5 from the Normal distribution with mean 8 and standard deviation 2: 4.47 5.51 8.1 11.63 7.91 Although we know the true value of μ suppose we pretend that we do not and we test the hypotheses Ho : μ-5.6 a:μ 5.6 at the α 0.05 significance level. What is the power of the test against the alternative μ 8 (the actual population mean)?...
Software can generate samples from (almost) exactly Normal distributions. Here is a random sample of size 5 from the Normal distribution with mean 8 and standard deviation 2: 4.47 5.51 8.1 11.63 7.91 Although we know the true value of μ suppose we pretend that we do not and we test the hypotheses Ho : μ-5.6 a:μ 5.6 at the α 0.05 significance level. What is the power of the test against the alternative μ 8 (the actual population mean)?...
Most questions answered within 3 hours.
-
Please answer true or false. Words
cannot be changed or added in to make it true...
asked 50 minutes ago -
An empty test tube weighs 15.923 grams. Then,
MgCl2•6H2O is added into the test tube. After...
asked 51 minutes ago -
(a) A piston at 6.1 atm contains a gas that occupies a volume of
3.5 L....
asked 50 minutes ago -
Assume memory access is 10 units of time and disk access is
10000 units of time....
asked 1 hour ago -
1. Are all good samples random?
2. Magazines often report surveys giving statistics such as “63%...
asked 1 hour ago -
Under all the various types of market structures, firms
must eventually earn some economic profits for...
asked 1 hour ago -
Consider the following fitness regime for a single locus trait
with two co-dominant alleles: w11 =...
asked 1 hour ago -
A large cable company reports the following.
80% of its customers subscribe to its cable TV...
asked 1 hour ago -
Please answer the question in brief.
Discuss the role of ERP in organizations. Are ERP tools...
asked 1 hour ago -
Discuss the pros and cons of collaborative software such
as SameTime. Does it increase productivity? What...
asked 1 hour ago -
Buying your in-laws a gift because it’s expected is
due to the ____________ motive of gift-giving....
asked 1 hour ago -
Calculate the expected value, the variance, and the standard
deviation of the given random variable X....
asked 2 hours ago