
Homework Answers
Derivation of Backpropagation algorithm
In machine learning, specifically deep learning, backpropagation (backprop,[1]BP) is an algorithm widely used in the training of feedforward neural networks for supervised learning; generalizations exist for other artificial neural networks (ANNs), and for functions generally.[2] Backpropagation efficiently computes the gradient of the loss function with respect to the weights of the network for a single input-output example. This makes it feasible to use gradient methods for training multi-layer networks, updating weights to minimize loss; commonly one uses gradient descent or variants such as stochastic gradient descent. The backpropagation algorithm works by computing the gradient of the loss function with respect to each weight by the chain rule, iterating backwards one layer at a time from the last layer to avoid redundant calculations of intermediate terms in the chain rule; this is an example of dynamic programming.[3]
The term backpropagation strictly refers only to the
algorithm for computing the gradient, but it is often used loosely
to refer to the entire learning algorithm, also including how the
gradient is used, such as by stochastic gradient
descent.[4] Backpropagation generalizes the gradient
computation in the Delta rule, which is the single-layer version of
backpropagation, and is in turn generalized by automatic
differentiation, where backpropagation is a special case of reverse
accumulation (or "reverse mode").[5] The term
backpropagation and its general use in neural networks was
announced in Rumelhart, Hinton & Williams (1986a), then
elaborated and popularized in Rumelhart, Hinton & Williams
(1986b), but the technique was independently rediscovered many
times, and had many predecessors dating to the 1960s; see §
History.[6] A modern overview is given in Goodfellow,
Bengio & Courville (2016).[7]In machine learning,
specifically deep learning, backpropagation
(backprop,[1]BP) is an
algorithm widely used in the training of feedforward neural
networks for supervised learning; generalizations exist for other
artificial neural networks (ANNs), and for functions
generally.[2] Backpropagation efficiently computes the
gradient of the loss function with respect to the weights of the
network for a single input-output example. This makes it feasible
to use gradient methods for training multi-layer networks, updating
weights to minimize loss; commonly one uses gradient descent or
variants such as stochastic gradient descent. The backpropagation
algorithm works by computing the gradient of the loss function with
respect to each weight by the chain rule, iterating backwards one
layer at a time from the last layer to avoid redundant calculations
of intermediate terms in the chain rule; this is an example of
dynamic programming.[3]
Overview
Backpropagation computes the gradient in weight space of a feedforward neural network, with respect to a loss function. Denote:
: input (vector of features)
: target output
For classification, output will be a vector of class probabilities (e.g., (0.1,0.7,0.2), and target output is a specific class, encoded by the one-hot/dummy variable (e.g., (0,1,0)).
: loss function or "cost function"
For classification, this is usually cross entropy (XC, log loss), while for regression it is usually squared error loss (SEL).
: the number of layers
: the weights between layer
and
, where
is the weight between the
-th node in layer
-th node in layer
: activation functions at layer
For classification the last layer is usually the logistic function for binary classification, and softmax (softargmax) for multi-class classification, while for the hidden layers this was traditionally a sigmoid function (logistic function or others) on each node (coordinate), but today is more varied, with rectifier (ramp, ReLU) being common.
In the derivation of backpropagation, other intermediate quantities are used; they are introduced as needed below. Bias terms are not treated specially, as they correspond to a weight with a fixed input of 1. For the purpose of backpropagation, the specific loss function and activation functions don't matter, so long as they and their derivatives can be evaluated efficiently.
The overall network is then a combination of function composition and matrix multiplication:

For a training set there will be a set of input-output
pairs,




Note the distinction: during model evaluation, the weights are fixed, while the inputs vary (and the target output may be unknown), and the network ends with the output layer (it does not include the loss function). During model training, the input-output pair is fixed, while the weights vary, and the network ends with the loss function.
Backpropagation computes the gradient for a fixed
input-output pair 

Informally, the key point is that since the only way a weight in




Backpropagation can be expressed for simple feedforward networks in terms of matrix multiplication, or more generally in terms of the adjoint graph.
Matrix multiplication[edit]
For the basic case of a feedforward network, where nodes in each layer are connected only to nodes in the immediate next layer (without skipping any layers), and there is a loss function that computes a scalar loss for the final output, backpropagation can be understood simply by matrix multiplication.[c] Essentially, backpropagation evaluates the expression for the derivative of the cost function as a product of derivatives between each layer from left to right – "backwards" – with the gradient of the weights between each layer being a simple modification of the partial products (the "backwards propagated error").
Given an input-output pair 

In order to compute this, one starts with the input 


The derivative of the loss in terms of the inputs is given by
the chain rule; note that each term is a total derivative,
evaluated at the value of the network (at each node) on the input

These terms are: the derivative of the loss function;[d] the derivatives of the activation functions;[e] and the matrices of weights:[f]

The gradient 

Backpropagation then consists essentially of evaluating this expression from right to left (equivalently, multiplying the previous expression for the derivative from left to right), computing the gradient at each layer on the way; there is an added step, because the gradient of the weights isn't just a subexpression: there's an extra multiplication.
Introducing the auxiliary quantity

Note that
The gradient of the weights in layer

The factor of is because the weights
The

The gradients of the weights can thus be computed using a few matrix multiplications for each level; this is backpropagation.
Compared with naively computing forwards (using the

there are two key differences with backpropagation:
- Computing
- Multiplying starting from
– propagating the error backwards – means that each step simply multiplies a vector (
and derivatives of activations
. By contrast, multiplying forwards, starting from the changes at an earlier layer, means that each multiplication multiplies a matrix by a matrix. This is much more expensive, and corresponds to tracking every possible path of a change in one layer
(for multiplying
by
, with additional multiplications for the derivatives of the activations), which unnecessarily computes the intermediate quantities of how weight changes affect the values of hidden nodes.
Adjoint graph
Intuition For more general graphs, and other advanced variations,
backpropagation can be understood in terms of automatic
differentiation, where backpropagation is a special case of reverse
accumulation (or "reverse mode").[5]
Motivation
The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to their correct output. The motivation for backpropagation is to train a multi-layered neural network such that it can learn the appropriate internal representations to allow it to learn any arbitrary mapping of input to output.[8]
Learning as an optimization problem
To understand the mathematical derivation of the backpropagation algorithm, it helps to first develop some intuition about the relationship between the actual output of a neuron and the correct output for a particular training example. Consider a simple neural network with two input units, one output unit and no hidden units, and in which each neuron uses a linear output (unlike most work on neural networks, in which mapping from inputs to outputs is non-linear)[g] that is the weighted sum of its input.

A simple neural network with two input units (each with a single input) and one output unit (with two inputs)
Initially, before training, the weights will be set randomly.
Then the neuron learns from training examples, which in this case
consist of a set of tuples 



As an example consider a regression problem using the square error as a loss:

where E is the discrepancy or error.
Consider the network on a single training case:

Error surface of a linear neuron for a single training case
However, the output of a neuron depends on the weighted sum of all its inputs:

where



Error surface of a linear neuron with two input weights
One commonly used algorithm to find the set of weights that minimizes the error is gradient descent. Backpropagation is then used to calculate the steepest descent direction in an efficient way.
Derivation[edit]
The gradient descent method involves calculating the derivative of the loss function with respect to the weights of the network. This is normally done using backpropagation. Assuming one output neuron,[h] the squared error function is

where


For each neuron

where the activation function {\displaystyle \varphi }

which has a convenient derivative of:

The input 




Finding the derivative of the error[edit]
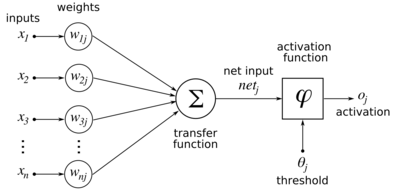
Diagram of an artificial neural network to illustrate the notation used here.
Calculating the partial derivative of the error with respect to
a weight 
|
|
|
(Eq. 1) |

In the last factor of the right-hand side of the above, only one
term in the sum,
|
|
|
(Eq. 2) |

If the neuron is in the first layer after the input layer,


The derivative of the output of neuron
|
|
|
(Eq. 3) |

which for the logistic activation function case is:

This is the reason why backpropagation requires the activation function to be differentiable. (Nevertheless, the ReLU activation function, which is non-differentiable at 0, has become quite popular, e.g. in AlexNet)
The first factor is straightforward to evaluate if the neuron is
in the output layer, because then
|
|
|
(Eq. 4) |

If the logistic function is used as activation and square error
as loss function we can rewrite it as 
However, if {\displaystyle j}
Considering 

and taking the total derivative with respect to
|
|
|
(Eq. 5) |

Therefore, the derivative with respect to 
Substituting Eq. 2, Eq. 3 Eq.4 and Eq. 5 in Eq. 1 we obtain:


with

if

To update the weight 






Loss function[edit]
Further information: Loss function
The loss function is a function that maps values of one or more variables onto a real number intuitively representing some "cost" associated with those values. For backpropagation, the loss function calculates the difference between the network output and its expected output, after a training example has propagated through the network.
Assumptions[edit]
The mathematical expression of the loss function must fulfill
two conditions in order for it to be possibly used in
backpropagation.[9] The first is that it can be written
as an average 



Example loss function[edit]
Let 

Select an error function 


The error function over

Is BP equal to MLP
Multi Layer Perceptron training algorithm for MLPs is BP which is an extended form of the method used to train the perceptron. This algorithm entails a backward flow of the error corrections through each neuron in the network. The process of adjusting the weights and biases of a perceptron or MLP is known as training. The perceptron algorithm (for training simple perceptrons) consists of comparing the output of the perceptron with an associated target value. The most common training algorithm for MLPs is BP which is an extended form of the method used to train the perceptron. This algorithm entails a backward flow of the error corrections through each neuron in the network. In the most basic form, an ANN requires an input and should be associated with a reference which it tracks during each training iteration. The output, at the end of each training epoch, is compared with the reference and a corresponding adaptation of the connectionist weights are carried out. This is repeated till the output of the ANN is nearly equal to that of the reference. One cycle through the complete training set forms one epoch. The above is repeated till MSE meets the performance criteria. While repeating the above the number of epoch elapsed is counted. A few methods used for MLP training includes Gradient Descent BP (GDBP), Gradient Descent with Momentum BP (GDMBP), Gradient Descent with Adaptive Learning Rate BP (GDALRBP), Gradient Descent with Adaptive Learning Rate and Momentum BP (GDALMBP) and Gradient Descent with LevenbergMarquardt BP (GDLMBP).
Is BP equal to supervised learning algorithm
BP is a supervised learning algorithm that learns a function f (·): Rm → Ro by training on a data set, where m is the number of dimensions for input and o is the number of dimensions for output.
Add Answer to:
Answer Each Question (3 points each) • Describe the derivation of BP algorithm. • Is BP...
Analytics question: Describe the relationship between a supervised learning classifier and a set of linear equations.
Analytics question: Describe the relationship between a supervised learning classifier and a set of linear equations.
Analytics question: Describe the relationship between a supervised learning classifier and a set of linear equations.
Analytics question: Describe the relationship between a supervised learning classifier and a set of linear equations.
For the following set of points, describe how the CLOSEST-PAIR algorithm finds a closest pair of points: (3) (3,2),(2,1)...
For the following set of points, describe how the CLOSEST-PAIR algorithm finds a closest pair of points: (3) (3,2),(2,1),(2,3),(1,2),(3,1),(2,2),(1,3),(3,−1),(5,−2)
Describe at least 3 physiologic variables that can change BP. How do these factors influence BP...
Describe at least 3 physiologic variables that can change BP. How do these factors influence BP (raise or lower) and why/how?
3. [15 marks] Describe an algorithm in pseudocode that locates an element in a list of...
 3. [15 marks] Describe an algorithm in pseudocode that locates an element in a list of increasing integers by successively splitting the list into four sublists of equal size (or as close to equal size as possible) and restricting the search to the appropriate piece. procedure tetrary search(x: integer, a1, a2, ..., an: increasing integers) (location is the subscript of the term equal to x, or 0 if not found)
3. [15 marks] Describe an algorithm in pseudocode that locates...
3. [15 marks] Describe an algorithm in pseudocode that locates an element in a list of increasing integers by successively splitting the list into four sublists of equal size (or as close to equal size as possible) and restricting the search to the appropriate piece. procedure tetrary search(x: integer, a1, a2, ..., an: increasing integers) (location is the subscript of the term equal to x, or 0 if not found)
3. [15 marks] Describe an algorithm in pseudocode that locates...
9. (5 points) Please describe an algorithm that takes as input a list of n integers...
 9. (5 points) Please describe an algorithm that takes as input a list of n integers and finds the number of negative integers in the list. 10. (5 points) Please devise an algorithm that finds all modes. (Recall that a list of integers is nondecreasing if each term of the list is at least as large as the preceding term.) 11. (5 points) Please find the least integer n such that f() is 0(3") for each of these functions f()...
9. (5 points) Please describe an algorithm that takes as input a list of n integers and finds the number of negative integers in the list. 10. (5 points) Please devise an algorithm that finds all modes. (Recall that a list of integers is nondecreasing if each term of the list is at least as large as the preceding term.) 11. (5 points) Please find the least integer n such that f() is 0(3") for each of these functions f()...
2. Describe why finding a polynomial-time algorithm for a NP-complete problem would answer the question if...
 2. Describe why finding a polynomial-time algorithm for a NP-complete problem would answer the question if P = NP. What would the answer be? (7-10 sentences minimum)
2. Describe why finding a polynomial-time algorithm for a NP-complete problem would answer the question if P = NP. What would the answer be? (7-10 sentences minimum)
Dijkstra's Algorithm Using the following graph, please answer each question below. Dijkstra's Algorithm 5) Consider...
 Dijkstra's Algorithm
Using the following graph, please answer each question below.
Dijkstra's Algorithm 5) Consider the following graph: 80 70 90 60 10 Use Dijkstra's algorithm to find the costs of the shortest paths from A to each of the other vertices. Show your work at every step. a. b. Are any of the costs you computed using Dijkstra's algorithm in part (a) incorrect? Why or whynot? Explain how you can use Dijkstra's algorithm the recover the actual paths...
Dijkstra's Algorithm
Using the following graph, please answer each question below.
Dijkstra's Algorithm 5) Consider the following graph: 80 70 90 60 10 Use Dijkstra's algorithm to find the costs of the shortest paths from A to each of the other vertices. Show your work at every step. a. b. Are any of the costs you computed using Dijkstra's algorithm in part (a) incorrect? Why or whynot? Explain how you can use Dijkstra's algorithm the recover the actual paths...
Question 24 (4 points) Describe the "structural cap model" for microtubules and the basis for the...
 Question 24 (4 points) Describe the "structural cap model" for microtubules and the basis for the "catastrophic disassembly of the microtubule bp.
Question 24 (4 points) Describe the "structural cap model" for microtubules and the basis for the "catastrophic disassembly of the microtubule bp.
Question 9 0 / 10 points Describe the basic operations that can be performed on a...
 Question 9 0 / 10 points Describe the basic operations that can be performed on a stack. Write an algorithm (using bullet points or a description, not Java or C) which shows how to remove an item from a stack that is implemented as an array. No text entered - This question has not been graded. The correct answer is not displayed for Written Response type questions. Question 10 0 / 10 points What are the main characteristics of a...
Question 9 0 / 10 points Describe the basic operations that can be performed on a stack. Write an algorithm (using bullet points or a description, not Java or C) which shows how to remove an item from a stack that is implemented as an array. No text entered - This question has not been graded. The correct answer is not displayed for Written Response type questions. Question 10 0 / 10 points What are the main characteristics of a...
 3. [15 marks] Describe an algorithm in pseudocode that locates an element in a list of increasing integers by successively splitting the list into four sublists of equal size (or as close to equal size as possible) and restricting the search to the appropriate piece. procedure tetrary search(x: integer, a1, a2, ..., an: increasing integers) (location is the subscript of the term equal to x, or 0 if not found)
3. [15 marks] Describe an algorithm in pseudocode that locates...
3. [15 marks] Describe an algorithm in pseudocode that locates an element in a list of increasing integers by successively splitting the list into four sublists of equal size (or as close to equal size as possible) and restricting the search to the appropriate piece. procedure tetrary search(x: integer, a1, a2, ..., an: increasing integers) (location is the subscript of the term equal to x, or 0 if not found)
3. [15 marks] Describe an algorithm in pseudocode that locates...
 9. (5 points) Please describe an algorithm that takes as input a list of n integers and finds the number of negative integers in the list. 10. (5 points) Please devise an algorithm that finds all modes. (Recall that a list of integers is nondecreasing if each term of the list is at least as large as the preceding term.) 11. (5 points) Please find the least integer n such that f() is 0(3") for each of these functions f()...
9. (5 points) Please describe an algorithm that takes as input a list of n integers and finds the number of negative integers in the list. 10. (5 points) Please devise an algorithm that finds all modes. (Recall that a list of integers is nondecreasing if each term of the list is at least as large as the preceding term.) 11. (5 points) Please find the least integer n such that f() is 0(3") for each of these functions f()...
 2. Describe why finding a polynomial-time algorithm for a NP-complete problem would answer the question if P = NP. What would the answer be? (7-10 sentences minimum)
2. Describe why finding a polynomial-time algorithm for a NP-complete problem would answer the question if P = NP. What would the answer be? (7-10 sentences minimum)
 Dijkstra's Algorithm
Using the following graph, please answer each question below.
Dijkstra's Algorithm 5) Consider the following graph: 80 70 90 60 10 Use Dijkstra's algorithm to find the costs of the shortest paths from A to each of the other vertices. Show your work at every step. a. b. Are any of the costs you computed using Dijkstra's algorithm in part (a) incorrect? Why or whynot? Explain how you can use Dijkstra's algorithm the recover the actual paths...
Dijkstra's Algorithm
Using the following graph, please answer each question below.
Dijkstra's Algorithm 5) Consider the following graph: 80 70 90 60 10 Use Dijkstra's algorithm to find the costs of the shortest paths from A to each of the other vertices. Show your work at every step. a. b. Are any of the costs you computed using Dijkstra's algorithm in part (a) incorrect? Why or whynot? Explain how you can use Dijkstra's algorithm the recover the actual paths...
 Question 24 (4 points) Describe the "structural cap model" for microtubules and the basis for the "catastrophic disassembly of the microtubule bp.
Question 24 (4 points) Describe the "structural cap model" for microtubules and the basis for the "catastrophic disassembly of the microtubule bp.
 Question 9 0 / 10 points Describe the basic operations that can be performed on a stack. Write an algorithm (using bullet points or a description, not Java or C) which shows how to remove an item from a stack that is implemented as an array. No text entered - This question has not been graded. The correct answer is not displayed for Written Response type questions. Question 10 0 / 10 points What are the main characteristics of a...
Question 9 0 / 10 points Describe the basic operations that can be performed on a stack. Write an algorithm (using bullet points or a description, not Java or C) which shows how to remove an item from a stack that is implemented as an array. No text entered - This question has not been graded. The correct answer is not displayed for Written Response type questions. Question 10 0 / 10 points What are the main characteristics of a...
Most questions answered within 3 hours.
-
1. Review the Nike’s marketing strategy. You must include the
company’s target market, possible market segmentation,...
asked 11 minutes ago -
One of the major advantages of ______________ is to enhance
security for private networks by keeping...
asked 17 minutes ago -
Book:
Title: Framework for
Marketing Management, 15th edition
Author/s: Philip T.
Kotler, Kevin Lane Keller
1....
asked 25 minutes ago -
Given Uber’s recent corporate turbulence and ongoing
initiatives, provide a holistic situational analysis of the
environment...
asked 29 minutes ago -
A sculptor has hung up a 42.0 kg horizontal rod of length 4.80 m
. One...
asked 32 minutes ago -
What is the purpose of the 2' hydroxyl group in RNA? What is
the reason this...
asked 50 minutes ago -
You currently have 20,000X ethidium bromide. You want to make
250 mL of 1X ethidium bromide...
asked 1 hour ago -
What mass of lead is needed to absorb 348 J of heat if the temp
of...
asked 1 hour ago -
Explain the difference between an auction with reserve
and an auction without reserve. if not specified,...
asked 1 hour ago -
Write the net ionic equation for the precipitation reaction that
occurs when aqueous solutions of aluminum...
asked 1 hour ago -
How do we find the slope distance, given the horizontal distance
and the zenith angle?
For...
asked 1 hour ago -
The table to the right lists probabilities for the corresponding
numbers of girls in three births....
asked 1 hour ago