
Homework Answers
ANSWER:
The least square loss is basically the sum of squares of the residuals. A residual is defined as the predicted value subtracted from the true value.
Predicted value at (x1, x2) = sigmoid(w1x1 + w2x2 + b)
Considering the single piece of training data and the given weights, the loss is equal to
L = (true value - observed value)2
= (0 - sigmoid(w1x1 + w2x2 + b))2
= (sigmoid( (1)(1)+ (1)(-1) + 1))2
= (sigmoid(1))2
We are asked to perform gradient descent, this means we need to change the values of the weights and biases in such a way that the loss is decreased as much as possible.
To find this optimal change at the given point, we consider the loss function without plugging in the values of weights and biases, i.e
L(w1, w2 , b) = (sigmoid(w1(1)+ w2 (-1)+ b))2
= (sigmoid(w1 - w2+ b))2
Now, we use the fact that partial derivatives indicate the change in value with respect to the given weight.
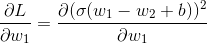

 (Since
(Since
 )
)
Similarly

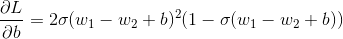
Now for the given weights,
 this means as w1 is increasing loss is increasing
therefore to decrease it, we have to take a step in the negative
direction. Since the step size has already been mentioned. The new
weight w1 = 1 - 2 =
-1
this means as w1 is increasing loss is increasing
therefore to decrease it, we have to take a step in the negative
direction. Since the step size has already been mentioned. The new
weight w1 = 1 - 2 =
-1
 Similar to w1 , b becomes 1-2 i.e b =
-1
Similar to w1 , b becomes 1-2 i.e b =
-1
 This is opposite to the above case and hence we increase the weight
for w2 i.e w2 =
3
This is opposite to the above case and hence we increase the weight
for w2 i.e w2 =
3
NOTE:We can observe that the loss has not decreased, after taking the step. This is because the step size being too big, it overshooted.
Add Answer to:
Exercise Optimization in neural network Consider a very simple neural network with two input values, one...
5. (10 points) Optimization in neural network Consider a very simple neural network with two input...
 5. (10 points) Optimization in neural network Consider a very simple neural network with two input values, one output value, and a single neuron with sigmoid activation. Each input to the neuron has an associated weight, and the neuron has a bias. So the network represents functions of the form o(W121 + W222 +b). We train the neural network using least squares loss on a single piece of training data ((1, -1),0). Initially all weights and biases are set to...
5. (10 points) Optimization in neural network Consider a very simple neural network with two input values, one output value, and a single neuron with sigmoid activation. Each input to the neuron has an associated weight, and the neuron has a bias. So the network represents functions of the form o(W121 + W222 +b). We train the neural network using least squares loss on a single piece of training data ((1, -1),0). Initially all weights and biases are set to...
1. Consider a neural network, which contains one hidden layer and an output layer with one...
 1. Consider a neural network, which contains one hidden layer and an output layer with one output unit. Let the hidden units have negative sigmoid as the activation function, which is formulated as 1 n(v) 1 + exp(-1) and the output unit has a linear activation function in which the output is equal to the activation input). (a) Show that the derivative of the negative sigmoid obeys the following relation dn(v) dv = n(v)(1 + n(v)) (b) Let the cost...
1. Consider a neural network, which contains one hidden layer and an output layer with one output unit. Let the hidden units have negative sigmoid as the activation function, which is formulated as 1 n(v) 1 + exp(-1) and the output unit has a linear activation function in which the output is equal to the activation input). (a) Show that the derivative of the negative sigmoid obeys the following relation dn(v) dv = n(v)(1 + n(v)) (b) Let the cost...
1. Compared with PID Control, what are the advantages and disadvantages of Neural Network Control...
 1. Compared with PID Control, what are the advantages and disadvantages of Neural Network Control? 2. The multi-layer neural network shown in Figure I has two inputs and one output. The network has two neurons in a hidden layer. The network is to be trained with backpropagation algorithm. Each neuron has a sigmoid activation function: Assume that the biases to the neurons is +1 and the learning rate is 1. The network has the following initial weights: (w). w1 wa1...
1. Compared with PID Control, what are the advantages and disadvantages of Neural Network Control? 2. The multi-layer neural network shown in Figure I has two inputs and one output. The network has two neurons in a hidden layer. The network is to be trained with backpropagation algorithm. Each neuron has a sigmoid activation function: Assume that the biases to the neurons is +1 and the learning rate is 1. The network has the following initial weights: (w). w1 wa1...
4.7. Consider a two-layer feedforward ANN with two inputs a and b, one hidden unit c, and one output unit d. This net...
 4.7. Consider a two-layer feedforward ANN with two inputs a and b, one hidden unit c, and one output unit d. This network has five weights (wca, Wcb, Wco, Wse, Wao). where wro represents the threshold weight for unit x. Initialize these weights to the values (.1,.1,.1,.1,.1), then give their values after each of the first two training iterations of the BACKPROPAGATION algorithm. Assume learning rte '-.3, momentum α-: 0.9, incremental weight updates, and the following training examples: 0 1...
4.7. Consider a two-layer feedforward ANN with two inputs a and b, one hidden unit c, and one output unit d. This network has five weights (wca, Wcb, Wco, Wse, Wao). where wro represents the threshold weight for unit x. Initialize these weights to the values (.1,.1,.1,.1,.1), then give their values after each of the first two training iterations of the BACKPROPAGATION algorithm. Assume learning rte '-.3, momentum α-: 0.9, incremental weight updates, and the following training examples: 0 1...
A deep learning problem. The following matrices describing a neural network were uncovered by scientists. The...
 A deep learning problem.
The following matrices describing a neural network were uncovered by scientists. The weights for the hidden layer are given in the matrix W[1] = [0 1] The bias for the hidden layer is given in the vector b[1] = [1] The weights for the output layer are given in the vector W[2] [8] 0 1 The biases for the output layer are 612] = -0.5 0.75 The input X is given in the vector X 1.25...
A deep learning problem.
The following matrices describing a neural network were uncovered by scientists. The weights for the hidden layer are given in the matrix W[1] = [0 1] The bias for the hidden layer is given in the vector b[1] = [1] The weights for the output layer are given in the vector W[2] [8] 0 1 The biases for the output layer are 612] = -0.5 0.75 The input X is given in the vector X 1.25...
Neural Networks We will now build some neural networks to represent basic boolean functions. For simplicity, we use the threshold function as our basic units instead of the sigmoid function, where th...
 Neural Networks
We will now build some neural networks to represent basic boolean functions. For simplicity, we use the threshold function as our basic units instead of the sigmoid function, where threshold(t) +1 if the input is greater than 0, and 0 otherwise, we have inputs xi (+1, 0) and weights yī (possible values-l, 0, 1). Suppose we are given boolean input data xi where 1 represents TRUE and 0 represents FALSE. The boolean NOT function can be represented by...
Neural Networks
We will now build some neural networks to represent basic boolean functions. For simplicity, we use the threshold function as our basic units instead of the sigmoid function, where threshold(t) +1 if the input is greater than 0, and 0 otherwise, we have inputs xi (+1, 0) and weights yī (possible values-l, 0, 1). Suppose we are given boolean input data xi where 1 represents TRUE and 0 represents FALSE. The boolean NOT function can be represented by...
Draw a fully connected neural network with 1 hidden layer where the number of units input, hidden layer, and output layer are 3, 2, 1, respectively. . (5+5+5+5) a. Show all the weight matrices a...
 Draw a fully connected neural network with 1 hidden layer where the number of units input, hidden layer, and output layer are 3, 2, 1, respectively. . (5+5+5+5) a. Show all the weight matrices and their dimensions for this neural network. b. Label the network connections using the weight values (e.g., w12, w23). c. Total how many weights do you need to train in this neural network? . Explain supervised and unsupervised learning in your own words. (10)
Draw a...
Draw a fully connected neural network with 1 hidden layer where the number of units input, hidden layer, and output layer are 3, 2, 1, respectively. . (5+5+5+5) a. Show all the weight matrices and their dimensions for this neural network. b. Label the network connections using the weight values (e.g., w12, w23). c. Total how many weights do you need to train in this neural network? . Explain supervised and unsupervised learning in your own words. (10)
Draw a...
will give thumbs up to 3/5 answers to question Select all reasonable methods for handling local...
will give thumbs up to 3/5 answers to question Select all reasonable methods for handling local minima when training an ANN (Artificial Neural Networks): restart the training several times from the same initial state use simulated annealing perturb the weight matrix slightly and continue the training use a momentum term use full gradient descent add an additional hidden layer Select all that are true in regard to the hidden units of a fully-connected ANN: unlike decision tree nodes, ANN nodes...
 5. (10 points) Optimization in neural network Consider a very simple neural network with two input values, one output value, and a single neuron with sigmoid activation. Each input to the neuron has an associated weight, and the neuron has a bias. So the network represents functions of the form o(W121 + W222 +b). We train the neural network using least squares loss on a single piece of training data ((1, -1),0). Initially all weights and biases are set to...
5. (10 points) Optimization in neural network Consider a very simple neural network with two input values, one output value, and a single neuron with sigmoid activation. Each input to the neuron has an associated weight, and the neuron has a bias. So the network represents functions of the form o(W121 + W222 +b). We train the neural network using least squares loss on a single piece of training data ((1, -1),0). Initially all weights and biases are set to...
 1. Consider a neural network, which contains one hidden layer and an output layer with one output unit. Let the hidden units have negative sigmoid as the activation function, which is formulated as 1 n(v) 1 + exp(-1) and the output unit has a linear activation function in which the output is equal to the activation input). (a) Show that the derivative of the negative sigmoid obeys the following relation dn(v) dv = n(v)(1 + n(v)) (b) Let the cost...
1. Consider a neural network, which contains one hidden layer and an output layer with one output unit. Let the hidden units have negative sigmoid as the activation function, which is formulated as 1 n(v) 1 + exp(-1) and the output unit has a linear activation function in which the output is equal to the activation input). (a) Show that the derivative of the negative sigmoid obeys the following relation dn(v) dv = n(v)(1 + n(v)) (b) Let the cost...
 1. Compared with PID Control, what are the advantages and disadvantages of Neural Network Control? 2. The multi-layer neural network shown in Figure I has two inputs and one output. The network has two neurons in a hidden layer. The network is to be trained with backpropagation algorithm. Each neuron has a sigmoid activation function: Assume that the biases to the neurons is +1 and the learning rate is 1. The network has the following initial weights: (w). w1 wa1...
1. Compared with PID Control, what are the advantages and disadvantages of Neural Network Control? 2. The multi-layer neural network shown in Figure I has two inputs and one output. The network has two neurons in a hidden layer. The network is to be trained with backpropagation algorithm. Each neuron has a sigmoid activation function: Assume that the biases to the neurons is +1 and the learning rate is 1. The network has the following initial weights: (w). w1 wa1...
 4.7. Consider a two-layer feedforward ANN with two inputs a and b, one hidden unit c, and one output unit d. This network has five weights (wca, Wcb, Wco, Wse, Wao). where wro represents the threshold weight for unit x. Initialize these weights to the values (.1,.1,.1,.1,.1), then give their values after each of the first two training iterations of the BACKPROPAGATION algorithm. Assume learning rte '-.3, momentum α-: 0.9, incremental weight updates, and the following training examples: 0 1...
4.7. Consider a two-layer feedforward ANN with two inputs a and b, one hidden unit c, and one output unit d. This network has five weights (wca, Wcb, Wco, Wse, Wao). where wro represents the threshold weight for unit x. Initialize these weights to the values (.1,.1,.1,.1,.1), then give their values after each of the first two training iterations of the BACKPROPAGATION algorithm. Assume learning rte '-.3, momentum α-: 0.9, incremental weight updates, and the following training examples: 0 1...
 A deep learning problem.
The following matrices describing a neural network were uncovered by scientists. The weights for the hidden layer are given in the matrix W[1] = [0 1] The bias for the hidden layer is given in the vector b[1] = [1] The weights for the output layer are given in the vector W[2] [8] 0 1 The biases for the output layer are 612] = -0.5 0.75 The input X is given in the vector X 1.25...
A deep learning problem.
The following matrices describing a neural network were uncovered by scientists. The weights for the hidden layer are given in the matrix W[1] = [0 1] The bias for the hidden layer is given in the vector b[1] = [1] The weights for the output layer are given in the vector W[2] [8] 0 1 The biases for the output layer are 612] = -0.5 0.75 The input X is given in the vector X 1.25...
 Neural Networks
We will now build some neural networks to represent basic boolean functions. For simplicity, we use the threshold function as our basic units instead of the sigmoid function, where threshold(t) +1 if the input is greater than 0, and 0 otherwise, we have inputs xi (+1, 0) and weights yī (possible values-l, 0, 1). Suppose we are given boolean input data xi where 1 represents TRUE and 0 represents FALSE. The boolean NOT function can be represented by...
Neural Networks
We will now build some neural networks to represent basic boolean functions. For simplicity, we use the threshold function as our basic units instead of the sigmoid function, where threshold(t) +1 if the input is greater than 0, and 0 otherwise, we have inputs xi (+1, 0) and weights yī (possible values-l, 0, 1). Suppose we are given boolean input data xi where 1 represents TRUE and 0 represents FALSE. The boolean NOT function can be represented by...
 Draw a fully connected neural network with 1 hidden layer where the number of units input, hidden layer, and output layer are 3, 2, 1, respectively. . (5+5+5+5) a. Show all the weight matrices and their dimensions for this neural network. b. Label the network connections using the weight values (e.g., w12, w23). c. Total how many weights do you need to train in this neural network? . Explain supervised and unsupervised learning in your own words. (10)
Draw a...
Draw a fully connected neural network with 1 hidden layer where the number of units input, hidden layer, and output layer are 3, 2, 1, respectively. . (5+5+5+5) a. Show all the weight matrices and their dimensions for this neural network. b. Label the network connections using the weight values (e.g., w12, w23). c. Total how many weights do you need to train in this neural network? . Explain supervised and unsupervised learning in your own words. (10)
Draw a...
Most questions answered within 3 hours.
-
Which has the highest energy photons in each pair? a. light with
a wavelength of 5x10^3m...
asked 3 minutes ago -
1. When a TLC plate was developed, detection by UV
light showed a single spot at the...
asked 5 minutes ago -
What is the source of information from natural materials which
can be used to reconstruct climate...
asked 20 minutes ago -
The International Monetary Fund (IMF) has hired you as an
economist. Your assignment is to travel...
asked 24 minutes ago -
Brief Exercise 12-65
Profitability Ratios
Tinker Corporation operates in the highly competitive consulting
industry. Tinker's balance...
asked 50 minutes ago -
Consider Lewin's three-step process. Which of the three steps do
you thin would be hardest to...
asked 50 minutes ago -
A disabled tanker leaks kerosene (n = 1.20) into the
Persian Gulf, creating a large slick...
asked 1 hour ago -
5. Explain the condition for a DC motor to develop the
maximum power. If a DC...
asked 1 hour ago -
Compute the p[Ag] after 35.00 mL of 0.1 M silver nitrate has been
added to the...
asked 1 hour ago -
Walgreen Company (NYSE: WAG) is currently trading at $48.50 on
the NYSE. Walgreen Company is also...
asked 1 hour ago -
Based on historical data, your team knows what proportion of the
company's orders come from Males...
asked 1 hour ago -
8. Which of the following atoms has the largest magnitude
electron affinity?
(a) Sodium (Na)
(b)...
asked 1 hour ago