I will like to compare automobile producers. This assignment suppose to read data like div tags...
I will like to compare automobile producers. This assignment
suppose to read data like div tags a etc. And count occurrence of
them. 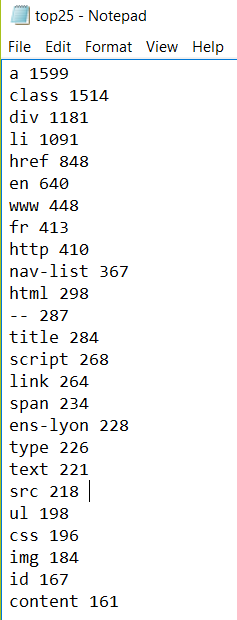
Reading from a URL while working with an API (using Mediawiki API as an example)
Input: Will be obtained from a URL using Mediawiki API -- starter code below
Output: Up to you... sort of.
What to submit: Upload a report (.pdf preferred) containing screenshots of code, output, and discussion/conclusions to d2l dropbox. Please also submit your code (yourlastname_lab3_p2.py)
Assignment Description: Compare how Wikipedia articles describe various items in the same category. The choice of items and category is up to you. Briefly describe the category, items, and your hypothesis in your report. Example categories/items/questions:
1) Automotive Brands; Toyota vs. Honda vs. Ford vs. Chevy; Do Wikipedia articles use significantly different terms when describing these brands? Are brands associated with certain countries described differently?
2) College football teams; similar questions as in (1)
3) Universities; similar questions as in (1)
4) Historical eras or significant events; Classical/bronze age history topics vs. Medieval vs. Modern; Does the terminology historians use change significantly (not the content being described -- obviously that will be different, but the historians' language itself)?
Detailed information about the API can be found here:
https://www.mediawiki.org/w/api.php?action=help&modules=query
https://www.mediawiki.org/wiki/Extension:TextExtracts
Starter code to help you get started using the Mediawiki API (NOTE: Use ps11. "requests" is a Python 2.7 module):
___________________________________________________
import requests
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'query',
'format': 'json',
'titles': 'University',
'prop': 'extracts',
'exintro': True,
'explaintext': True,
}
).json()
page = next(iter(response['query']['pages'].values()))
print(page['extract'])
__________________________________________________
Action, format, and title are standard API parameters.
prop: extracts -- uses TextExtract extension
exintro: True -- Return only content before the first section
explaintext: Return extracts as plain text instead of HTML
(see "detailed information" section's link for more info)
You may choose to work with extracts or full articles -- this is up to you.
Note: You may use one of the many "third-party" Python Wikipedia parsers available online if you choose. Please cite it properly if you do. I'm not 100% sure about this, but I think it may actually make the lab more difficult though... We could say this: "If you'd like to make Part II of the lab more challenging, learn how to use a third-party parser to extract text from Wikipedia articles".
Homework Answers
#include <iostream>
using namespace std;
int main()
{
string str = "C++ Programming is awesome";
char checkCharacter = 'a';
int count = 0;
for (int i = 0; i < str.size(); i++)
{
if (str[i] == checkCharacter)
{
++ count;
}
}
cout << "Number of " << checkCharacter << " = " << count;
return 0;
}
#include<iostream.h>
#include<conio.h>
#include<stdlib.h>
void main()
{
clrscr();
int i, count=0;
char str[1000], ch;
cout<<"Enter the String : ";
gets(str);
cout<<"Enter a character to find frequency : ";
cin>>ch;
for(i=0; str[i]!='\0'; i++)
{
if(ch==str[i])
{
count++;
}
}
cout<<"Frequency of the character "<<ch<<" = "<<count;
getch();
}
Add Answer to:
I will like to compare automobile producers. This assignment
suppose to read data like div tags...
I want to use BING API for web searching using python. Search result should only contain PDF. I a...
I want to use BING API for web searching using python. Search result should only contain PDF. I added the advanced operator (filetype: pdf) in the search query. But seems it not working. ******** Python code ************** import requests def bing_search(query): url = 'https://api.cognitive.microsoft.com/bing/v5.0' # query string parameters payload = {'q': query, 'filetype':'pdf','responseFilter':'Webpages'} # custom headers headers = {'Ocp-Apim-Subscription-Key': '9126a2280100424b90b85d764a18dc34'} # make GET request r = requests.get(url, params=payload, headers=headers) # get JSON response return r.json() j = bing_search('Machine Learning') print(j.get('webPages',...
Please read the article and answer about questions. You and the Law Business and law are...
Please read the article and answer about questions. You and the Law Business and law are inseparable. For B-Money, the two predictably merged when he was negotiat- ing a deal for his tracks. At other times, the merger is unpredictable, like when your business faces an unexpected auto accident, product recall, or government regulation change. In either type of situation, when business owners know the law, they can better protect themselves and sometimes even avoid the problems completely. This chapter...
Most questions answered within 3 hours.
-
Assembly Language:
Is it TRUE or FALSE:
Reduced Instruction Set Computers (RISC) are characterized
by:
Relatively...
asked 57 seconds ago -
Data from the Bureau of Labor Statistics’ Consumer Expenditure
Survey show that annual expenditures for cellular...
asked 1 minute ago -
A ball is thrown from the origo over a flat horizontal ground.
the x-axis is
horizontal...
asked 3 minutes ago -
Discuss graph representation, Breadth-first search and
Depth-first search. Use examples to highlight pros and
cons.
asked 10 minutes ago -
what are the impacts of droughts in east Africa on the:
1) economy:
2) agriculture:
3)...
asked 11 minutes ago -
Fleas can jump quite high; experiments show that they can reach
an altitude of 120 times...
asked 18 minutes ago -
The rate constant for this first-order reaction is 0.0520 s–1 at
400 °C.
A----> Product
After...
asked 23 minutes ago -
boolean a = ( true && false );
System.out.println( a );
what is the output of...
asked 27 minutes ago -
NEED HELP ASAP PLEASE! (I already answered 1-4)
The comparative financial statements of Marshall Inc. are...
asked 33 minutes ago -
PLEASE RESPOND TO POST. DO YOU AGREE OR DISAGREE? IF SO WHY.The
five traditional intelligence collection...
asked 33 minutes ago -
Grandma Assignment: This was my previous professor’s son’s
fourth grade homework assign- ment. Maxine, Mabel, Mavis,...
asked 34 minutes ago -
Write the pseudocode below as a working Python program.
Take a screenshot of your code and...
asked 49 minutes ago