PLEASE USE PYTHON training error should strictly decrease as the degree of the hypothesis polynomials increases....
PLEASE USE PYTHON
training error should strictly decrease as the degree of the hypothesis polynomials increases. That is because any high degree polynomial can "simulate" a lower degree polynomial by making it's high order coefficients zero. Thus nothing is lost and something might be gained by increasing the degree.
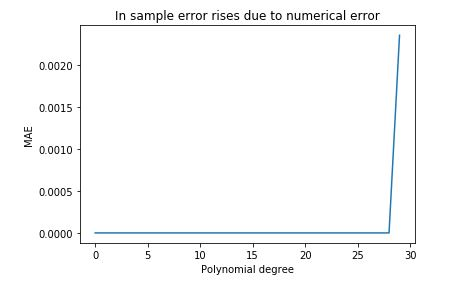
But the code below shows that in-sample error actually starts to increase on our dataset for polynomials of very high degree. Why do you think this happens?
CODE BELOW:
## Numerical error
xmin,xmax = 0,4*np.pi
x = np.linspace(xmin,xmax,1000)
D = 30
N = 100
shuff = np.random.permutation(len(x))
x_pts = np.array(sorted(x[shuff][:N]))
K = 200
train_vals = np.zeros(D*K).reshape(K,D)
test_vals = np.zeros(D*K).reshape(K,D)
noise = np.random.randn(N)
y = np.sin(x_pts)+ noise/7
for k in range(K):
shuff = np.random.permutation(len(x))
x_pts = np.array(sorted(x[shuff][:N]))
noise = np.random.randn(N)
y = np.sin(x_pts)+ noise/7
for i,deg in enumerate(range(D)):
X = np.ones(N*deg).reshape(N,deg)
for j in range(1,deg):
X[:,j] = x_pts**j
X_train,X_test,y_train,y_test = test_train_split(X,y,0.13)
w = linear_fit(X_train,y_train)
g_train = linear_predict(X_train,w)
g_test = linear_predict(X_test,w)
r_train = MAE(g_train,y_train)
r_test = MAE(g_test,y_test)
train_vals[k][i] = r_train
test_vals[k][i] = r_test
tr_vals = np.mean(train_vals,axis=0)
te_vals = np.mean(test_vals,axis=0)
plt.plot(range(D),tr_vals)
plt.title("In sample error rises due to numerical error")
plt.xlabel("Polynomial degree")
plt.ylabel("MAE")
#plt.axis([0,D,0,2])
plt.show()
Homework Answers
#python code is as follows
import numpy as np
import sklearn.metrics
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
xmin,xmax = 0,4*np.pi
x = np.linspace(xmin,xmax,1000)
D = 30
N = 100
shuff = np.random.permutation(len(x))
x_pts = np.array(sorted(x[shuff][:N]))
K = 200
train_vals = np.zeros(D*K).reshape(K,D)
test_vals = np.zeros(D*K).reshape(K,D)
noise = np.random.randn(N)
y = np.sin(x_pts)+ noise/7
for k in range(K):
shuff = np.random.permutation(len(x))
x_pts = np.array(sorted(x[shuff][:N]))
noise = np.random.randn(N)
y_pts = np.sin(x_pts)+ noise/7
for i,deg in enumerate(range(D)):
X = np.ones(N*deg).reshape(N,deg)
for j in range(1,deg):
X[:,j] = x_pts**j
X_train,X_test,y_train,y_test =
train_test_split(X,y,test_size=0.13)
w = LinearRegression().fit(X_train,y_train)
g_train = w.predict(X_train)
g_test = w.predict(X_test)
r_train
=sklearn.metrics.mean_absolute_error(g_train,y_train)
r_test = sklearn.metrics.mean_absolute_error(g_test,y_test)
train_vals[k][i] = r_train
test_vals[k][i] = r_test
tr_vals = np.mean(train_vals,axis=0)
te_vals = np.mean(test_vals,axis=0)
plt.plot(range(D),tr_vals)
plt.title("In sample error rises due to numerical error")
plt.xlabel("Polynomial degree")
plt.ylabel("MAE")
#plt.axis([0,D,0,2])
plt.show()
This is the graph from the code above, we can see the Error increases sharply due at higher degrees
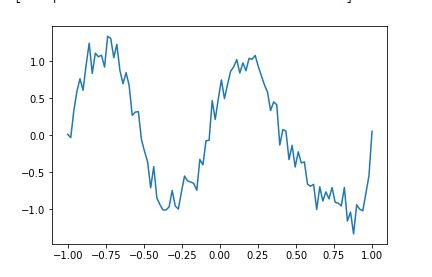
This what we get from y graph [ plt.plot(np.linspace(-1,1,100),y) ]
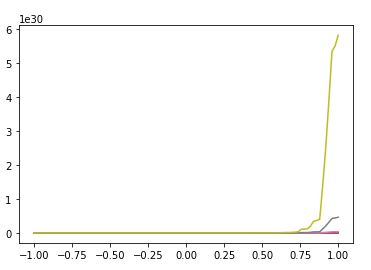
But the sudden change in the X component contribute to the abrupt change in error plt.plot(np.linspace(-1,1,100),X)
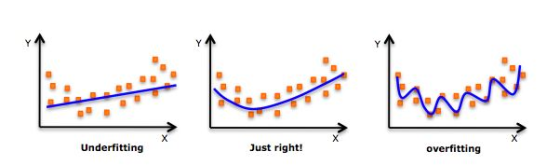
when you will fix it still you wont get the perfect answer due the over fitting in case of high power therefore you would have to try with some other model that move along sinusoidal wave not in the linear fashion ,the problem you are getting can be explained by this diagram.
Add Answer to:
PLEASE USE PYTHON
training error should strictly decrease as the degree of the
hypothesis polynomials increases....
Most questions answered within 3 hours.
-
Describe two obstacles that makes fixing atmospheric nitrogen
difficult.
asked 19 minutes ago -
Evelyn incorporates her sole proprietorship, transferring it to
newly formed Papaya Corporation. The assets transferred have...
asked 5 minutes ago -
Assume that in a hydrogen atom, the electron circles the nucleus
in a circle of radius...
asked 14 minutes ago -
A
752 mL sample of water was placed in a 1000 gram pan of aluminum.
The...
asked 7 minutes ago -
1 point) Given the significance level α=0.01 find the following:
(a) left-tailed z value z= (b)...
asked 8 minutes ago -
Calculate the expected value, the variance, and the standard
deviation of the given random variable X....
asked 10 minutes ago -
T
F 53) Most differences
between human groups are the result of biology rather than
culture....
asked 24 minutes ago -
A 5.20 mW helium neon laser emits a visible laser beam with a
wavelength of 633...
asked 27 minutes ago -
Assignment:
Your
organization has made a strategic decision
to
outsourcework
currently performed in house. You have...
asked 25 minutes ago -
A hospital performs 100 surgeries per week. The probability that
complications after surgery occur is 10%....
asked 26 minutes ago -
In preparing its cash flow statement for the year ended December
31, 2018, Green Co. gathered...
asked 28 minutes ago -
Donna is 18 years old and full time accounting student.She is
saving for an overseas holiday...
asked 28 minutes ago