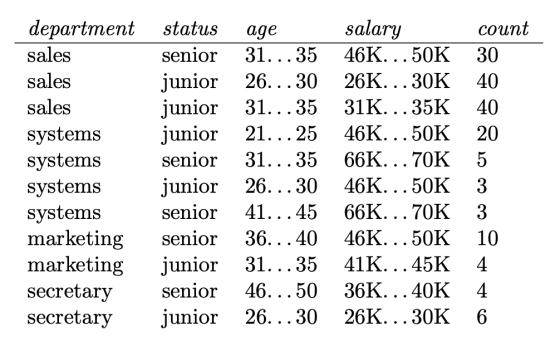
Given a data tuple having the values “systems,” “26...30,” and “46–50K” for the attributes department, age, and salarry, respectively, what would naiive Bayesian classification of the status for the tuple be?
The answer is "P(X|senior) = 0; P(X|junior) = 0.018. Thus, a naiive Bayesian classification predicts “junior”." Or I am not sure about that answer.
PLEASE explain the SOLUTION IN DETAIL.
Thank you!
Homework Answers

Add Answer to:
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age,...
Given a data tuple having the values “systems,” “26...30,” and “46–50K” for the attributes department, age,...
 Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
The following table consists of training data from an employee database. The data have been generalized....
 The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
 Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
 The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
Most questions answered within 3 hours.
-
An entomologist discovers a dung beetle rolling a ball of dung
along the ground, and decides...
asked 19 minutes ago -
Humans have used horses for transportation for millions of
years. Therefore, they will use horses for...
asked 2 hours ago -
The following are the Jensen Corporation's unit costs of making
and selling an item at a...
asked 2 hours ago -
Does direct Medicare reimbursement of Advanced practice nurses
increase access to their services?
asked 3 hours ago -
List and explain why a company would choose to use a
published
compensation survey vs. creating...
asked 3 hours ago -
A discrete random variable X can take values from 1 to 10. Find
the variance of...
asked 3 hours ago -
The primary financial goal of a corporation is to maximize:
shareholders wealth.
earnings per share.
stock...
asked 4 hours ago -
determine whether the vectors u=(1,2,3,), v=(-2,1,0) and
w=(1,0,1) are linearly dependent or independent.
asked 4 hours ago -
python
Define a function called print_values which takes a dictionary
object as a parameter. The function...
asked 5 hours ago -
In Chapter 1 you created a program named Triangle in
which you displayed a seven-line triangle...
asked 5 hours ago -
Research question: What are the differences between separately
stated and non separately stated transactions in an...
asked 5 hours ago -
By using Arduino write a code that connects two LEDs to two
push-buttons. Each button controls...
asked 6 hours ago