x y 5 6 6 9 7 11 8 13 9 14 10 15 11 15...
| x | y |
| 5 | 6 |
| 6 | 9 |
| 7 | 11 |
| 8 | 13 |
| 9 | 14 |
| 10 | 15 |
| 11 | 15 |
| 12 | 13 |
a) Generate a model for y as a function of x
b) Is this model useful? Justify your conclusion based on
i) R2 adjusted,
ii) Hypothesis test for model coefficient,
iii) overall model adequacy test and
iv) regression assumptions
c) If needed, modify model as appropriate and generate the new model.
*Complete all parts of the problem please, be as detailed with
explanation as possible.
Homework Answers
a)
Using R programming in R studio the following
Regression model for y as a function of x is generated:
############################################
R-codes:
# Reading data from Excel CSV file
xyData<-read.csv(file.choose(),header = T)
#Regression model generation
Model<-lm(y~x,data = xyData)
#Regression model outpt
summary(Model)
# Model adequacy and assumption plots
dev.new()
par(mfrow=c(2,2))
plot(Model)
################################################
Regression Model :
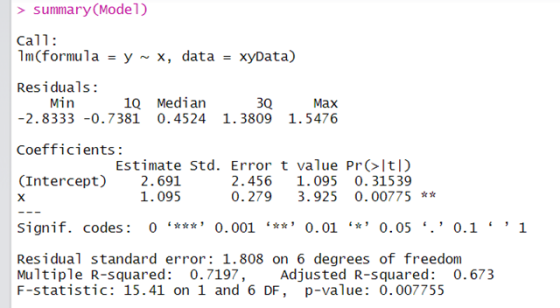
Regression Model Equation:
y =2.691 + 1.095 x .......(1)
b) Is this model useful based on...
i) R2 adjusted = 0.673 ==> It is good value make the model useful.
A model with a larger R-squared adjusted value means that the independent variables explain a larger percentage of the variation in the independent variable
ii) Hypothesis test for model coefficient
Ho: Slope of coefficient equal to Zero
H1: Slope of coefficient NOT equal to Zero
Since p-value of slope coefficient = 0.00775 which is less than 0.05 ( Alpha , level of significance)
Reject Ho
Conclusion : Independent variable 'x' is significantly predicting 'y'
iii) and iv) overall model adequacy test and regression assumptions
We will study following diagnostic plots from R output:
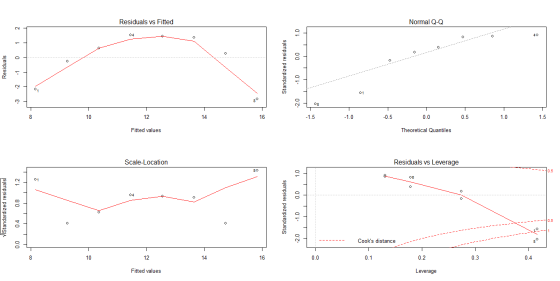
Linear Assumptions violated ( refer Residual vs Fitted plot )
Explanation: This plot shows if residuals have non-linear patterns. There could be a non-linear relationship between predictor variables and an outcome variable and the pattern could show up in this plot if the model doesn’t capture the non-linear relationship. If you find equally spread residuals around a horizontal line without distinct patterns, that is a good indication you don’t have non-linear relationships.
Normality Assumptions not violated ( refer Normal Q-Q plot )
Explanation: This plot shows if residuals are normally distributed. Do residuals follow a straight line well or do they deviate severely? It’s good if residuals are lined well on the straight dashed line.
Homoscedasticity Assumptions violated ( refer Scale-location plot )
Explanation: It’s also called Spread-Location plot. This plot shows if residuals are spread equally along the ranges of predictors. This is how you can check the assumption of equal variance (homoscedasticity). It’s good if you see a horizontal line with equally (randomly) spread points.
Influence cases and outliers Assumptions violated ( refer Residual vs Leverage plot)
Explanation: This plot helps us to find influential cases (i.e., subjects) if any. Not all outliers are influential in linear regression analysis (whatever outliers mean). Even though data have extreme values, they might not be influential to determine a regression line. That means, the results wouldn’t be much different if we either include or exclude them from analysis. They follow the trend in the majority of cases and they don’t really matter; they are not influential. On the other hand, some cases could be very influential even if they look to be within a reasonable range of the values. They could be extreme cases against a regression line and can alter the results if we exclude them from analysis.
## End of Answers ###
Consider the data in the chart below. a) Generate a model for y as a function...
Consider the data in the chart below. a) Generate a model for y as a function of x b. Is this model useful? Justify your conclusion (based on i) R2 adjusted, ii) Hypothesis test for model coefficient, iii) overall model adequacy test and iv) regression assumptions) c. If needed, modify model as appropriate and generate the new model. x y 5 6 6 9 7 11 8 13 9 14 10 15 11 15 12 13
x 10 8 13 9 11 14 6 4 12 7 5 y 9.14 8.13 8.75...
x 10 8 13 9 11 14 6 4 12 7 5 y 9.14 8.13 8.75 8.76 9.26 8.09 6.13 3.11 9.13 7.26 4.73 b. Find the linear correlation coefficient, r, then determine whether there is sufficient evidence to support the claim of a linear correlation between the two variables. The linear correlation coefficient is r =?
Find the correlation for the following dataset: x 10 8 13 9 11 14 6 4...
Find the correlation for the following dataset: x 10 8 13 9 11 14 6 4 12 7 5 y 7.46 6.77 12.74 7.11 7.81 8.84 6.08 5.39 8.15 6.42 5.73 I. 0.856 II. 0.502 III. 0.816 IV. 0.742
Consider the data: X- 1 Y- 6 3 14 5 7 2 20 9 11 10...
 Consider the data: X- 1 Y- 6 3 14 5 7 2 20 9 11 10 18 13 15 26 22 (a) Calculate the correlation between X and Y. 0.7399 (b) What percent of the variation in Y can be attributed to X? (Round to a whole percent) 55 % (c) Obtain the equation of the regression line for these data y = X +
Consider the data: X- 1 Y- 6 3 14 5 7 2 20 9 11 10 18 13 15 26 22 (a) Calculate the correlation between X and Y. 0.7399 (b) What percent of the variation in Y can be attributed to X? (Round to a whole percent) 55 % (c) Obtain the equation of the regression line for these data y = X +
12313werqw Honey 9 6 14 14 15 12 13 14 7 10 11 14 9 12 13 13 5 5 9 6 7 8 14 7 13 DM 5 5 12 6 11 7 13 7 7 5 6 5 9 5 13 11...
 12313werqw
Honey
9 6 14 14 15 12 13 14 7 10 11 14 9 12 13 13 5 5 9 6 7 8 14 7 13
DM 5 5 12 6 11 7 13 7 7 5 6 5 9 5 13 11 13 7 10 8
control 2 4 4 3 1 9 7 4 9 8 2 8 6 4 2 5
Calculate the mean, median and mode for each of the data
(Honey, DM and Control)....
12313werqw
Honey
9 6 14 14 15 12 13 14 7 10 11 14 9 12 13 13 5 5 9 6 7 8 14 7 13
DM 5 5 12 6 11 7 13 7 7 5 6 5 9 5 13 11 13 7 10 8
control 2 4 4 3 1 9 7 4 9 8 2 8 6 4 2 5
Calculate the mean, median and mode for each of the data
(Honey, DM and Control)....
Consider the following set of dependent and independent variables. Complete parts a through c below. y 10 11 14 14 20 24 26 32 저15597121521 x2 17 11 13 11 2 8 6 4 a. Using technology, construct a re...
 Consider the following set of dependent and independent variables. Complete parts a through c below. y 10 11 14 14 20 24 26 32 저15597121521 x2 17 11 13 11 2 8 6 4 a. Using technology, construct a regression model using both independent variables. y = 1 3.5734 ) + ( 0.9496 ) x 1 + (-0.4001 ) x2 (Round to four decimal places as needed.) b. Test the significance of each independent variable using a 0.10. Test the...
Consider the following set of dependent and independent variables. Complete parts a through c below. y 10 11 14 14 20 24 26 32 저15597121521 x2 17 11 13 11 2 8 6 4 a. Using technology, construct a regression model using both independent variables. y = 1 3.5734 ) + ( 0.9496 ) x 1 + (-0.4001 ) x2 (Round to four decimal places as needed.) b. Test the significance of each independent variable using a 0.10. Test the...
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 ...
 Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Question 8 to question 19 are true or false Subject: ADMN210- Applied Business Statistics 8) A...
 Question 8 to question 19 are true or false Subject: ADMN210-
Applied Business Statistics
8) A hypothesis test always contains the possibility of committing one of two types of errors callled Type I and Type lI errors d u e avoda b 9) The null hypothesis is rejected if the p-value is greater than the significance level 10) The probability of committing a Type I error is called the level of significance 11) In hypothesis testing the statistical conclusion is...
Question 8 to question 19 are true or false Subject: ADMN210-
Applied Business Statistics
8) A hypothesis test always contains the possibility of committing one of two types of errors callled Type I and Type lI errors d u e avoda b 9) The null hypothesis is rejected if the p-value is greater than the significance level 10) The probability of committing a Type I error is called the level of significance 11) In hypothesis testing the statistical conclusion is...
5. Goody 15 14 134 12 11- 10- 9-1 8-1 72 6 U BC вс 6...
 5. Goody 15 14 134 12 11- 10- 9-1 8-1 72 6 U BC вс 6 7 8 9 10 11 12 13 14 15 Good X From the figure, For an income of $15, the price of Y falls by ----, leading to a substitution effect of and an income effect of -
5. Goody 15 14 134 12 11- 10- 9-1 8-1 72 6 U BC вс 6 7 8 9 10 11 12 13 14 15 Good X From the figure, For an income of $15, the price of Y falls by ----, leading to a substitution effect of and an income effect of -
Exercise 2: The following sample observations were randomly selected. X Y 5 13 3 15 6...
Exercise 2: The following sample observations were randomly selected. X Y 5 13 3 15 6 7 3 12 4 13 4 11 6 9 8 5 a. Insert the trendline equation. b. Determine the coefficient of correlation and the coefficient of determination.
 Consider the data: X- 1 Y- 6 3 14 5 7 2 20 9 11 10 18 13 15 26 22 (a) Calculate the correlation between X and Y. 0.7399 (b) What percent of the variation in Y can be attributed to X? (Round to a whole percent) 55 % (c) Obtain the equation of the regression line for these data y = X +
Consider the data: X- 1 Y- 6 3 14 5 7 2 20 9 11 10 18 13 15 26 22 (a) Calculate the correlation between X and Y. 0.7399 (b) What percent of the variation in Y can be attributed to X? (Round to a whole percent) 55 % (c) Obtain the equation of the regression line for these data y = X +
 12313werqw
Honey
9 6 14 14 15 12 13 14 7 10 11 14 9 12 13 13 5 5 9 6 7 8 14 7 13
DM 5 5 12 6 11 7 13 7 7 5 6 5 9 5 13 11 13 7 10 8
control 2 4 4 3 1 9 7 4 9 8 2 8 6 4 2 5
Calculate the mean, median and mode for each of the data
(Honey, DM and Control)....
12313werqw
Honey
9 6 14 14 15 12 13 14 7 10 11 14 9 12 13 13 5 5 9 6 7 8 14 7 13
DM 5 5 12 6 11 7 13 7 7 5 6 5 9 5 13 11 13 7 10 8
control 2 4 4 3 1 9 7 4 9 8 2 8 6 4 2 5
Calculate the mean, median and mode for each of the data
(Honey, DM and Control)....
 Consider the following set of dependent and independent variables. Complete parts a through c below. y 10 11 14 14 20 24 26 32 저15597121521 x2 17 11 13 11 2 8 6 4 a. Using technology, construct a regression model using both independent variables. y = 1 3.5734 ) + ( 0.9496 ) x 1 + (-0.4001 ) x2 (Round to four decimal places as needed.) b. Test the significance of each independent variable using a 0.10. Test the...
Consider the following set of dependent and independent variables. Complete parts a through c below. y 10 11 14 14 20 24 26 32 저15597121521 x2 17 11 13 11 2 8 6 4 a. Using technology, construct a regression model using both independent variables. y = 1 3.5734 ) + ( 0.9496 ) x 1 + (-0.4001 ) x2 (Round to four decimal places as needed.) b. Test the significance of each independent variable using a 0.10. Test the...
 Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
Use least-square regression to fit the data with the following model y-a+bx+ x 6 9 15 16 y 10 15 2030 xjx2 x2 *1
 Question 8 to question 19 are true or false Subject: ADMN210-
Applied Business Statistics
8) A hypothesis test always contains the possibility of committing one of two types of errors callled Type I and Type lI errors d u e avoda b 9) The null hypothesis is rejected if the p-value is greater than the significance level 10) The probability of committing a Type I error is called the level of significance 11) In hypothesis testing the statistical conclusion is...
Question 8 to question 19 are true or false Subject: ADMN210-
Applied Business Statistics
8) A hypothesis test always contains the possibility of committing one of two types of errors callled Type I and Type lI errors d u e avoda b 9) The null hypothesis is rejected if the p-value is greater than the significance level 10) The probability of committing a Type I error is called the level of significance 11) In hypothesis testing the statistical conclusion is...
 5. Goody 15 14 134 12 11- 10- 9-1 8-1 72 6 U BC вс 6 7 8 9 10 11 12 13 14 15 Good X From the figure, For an income of $15, the price of Y falls by ----, leading to a substitution effect of and an income effect of -
5. Goody 15 14 134 12 11- 10- 9-1 8-1 72 6 U BC вс 6 7 8 9 10 11 12 13 14 15 Good X From the figure, For an income of $15, the price of Y falls by ----, leading to a substitution effect of and an income effect of -
Most questions answered within 3 hours.
-
3. Gains from trade
Consider two neighbouring island countries called Euphoria and
Contente. They each have...
asked 54 minutes ago -
A business executive has the option to invest money in two
plans: Plan A guarantees that...
asked 3 hours ago -
Hello, can someone please help me answer this question?
How much heat is absorbed by a...
asked 3 hours ago -
. A marketing researcher conducted a survey of 25 shoppers
randomly selected at the local mall...
asked 3 hours ago -
Create an comprehensive response to the
following:
Antimicrobial agents work on a multitude of microbes (bacteria,...
asked 3 hours ago -
6.13 LAB: Step counter. Section 6.3.
A pedometer treats walking 2,000 steps as walking 1 mile....
asked 3 hours ago -
(14.2) A block of mass m = 10 kg riding on a frictionless
horizontal plane is...
asked 3 hours ago -
Use any search engine to search for articles about Starbucks
partnership with Tata Companies in India...
asked 3 hours ago -
Let’s say that for some reason Bank Excess Reserves suddenly
increase sharply. What effect would this...
asked 3 hours ago -
Given:
Curent Assets: $600,000
Total Assets: $2,600,000
Current Liabilities: $500,000
Total Liabilities: $1,700,000
What is the...
asked 3 hours ago -
1. What is a “Bankster”? What is insider trading? Why is it
illegal?
2. What is...
asked 3 hours ago -
A transverse wave on a cord is given by
D(x,t)=0.18sin(2.7x−61.0t), where Dand x are in m...
asked 3 hours ago