In this exercise use the Peruvian blood pressure data set, provided in the file peruvian.txt. This dataset consists of variables possibly relating to blood pressures of n = 39 Peruvians who have moved from rural high altitude areas to urban lower altitude areas. The variables in this dataset are: Age, Years, Weight, Height, Calf, Pulse, Systol and Diastol. Before reading the data intoMATLAB, it can be viewed in a text editor.
This question involves the use of multiple linear regression on the Peru data set.
a) Use the fitlm() function to perform a multiple linear regression with Systol as the response and the other variables as predictors. Comment on the output. For example:
Is there a relationship between the predictors and the response?
Which predictors appear to have a statistically significant
relationship to the
response?
What does the coefficient for the Weight variable suggest?
Use the plotResiduals() and PlotDiagnostics function to produce diagnostic plots of the least squares regression fit. Comment on any problems you see with the fit.
b) Fit a with
Is there a relationship between the predictors and the response?
Which predictors appear to have a statistically significant
relationship to the
response?
What does the coefficient for the Weight variable suggest?
Use the plotResiduals() and PlotDiagnostics function to produce diagnostic plots of the least squares regression fit. Comment on any problems you see with the fit.
smaller model that only uses the predictors for which there is evidence of association the response. How well do the models in (a) and (b) fit the data?
c) Use the * symbol to fit linear regression models with interaction effects. Do any interactions appear to be statistically significant? Compare the model to the models in (a) and (b).
d) Using the information from the correlation matrix you computed above, develop a rational approach to fit a model. Which predictors have you picked and why? How well does the model fit the data? Compare this model to the previous models.

Homework Answers
This dataset consists of variables possibly relating to blood pressures of n = 39 Peruvians who have moved from rural high altitude areas to urban lower altitude areas (peru.txt). The variables in this dataset are:
Y = systolic blood pressure
X1 = age
X2 = years in urban area
X3 = X2
/X1 = fraction of life in urban area
X4 = weight (kg)
X5 = height (mm)
X6 = chin skinfold
X7 = forearm skinfold
X8 = calf skinfold
X9 = resting pulse rate
First, we run a multiple regression using all nine x-variables as predictors. The results are given below.

When looking at tests for individual variables, we see that p-values for the variables Height, Chin, Forearm,Calf, and Pulse are not at a statistically significant level. These individual tests are affected by correlations amongst the x-variables, so we will use the General Linear F procedure to see whether it is reasonable to declare that all five non-significant variables can be dropped from the model.
Next, consider testing:
H0 : β5 =
β6 = β7 =
β8 = β9 = 0
HA : at least one of {β5 ,
β6 , β7 ,
β8 , β9 } ≠ 0
within the nine variable model given above. If this null is not rejected, it is reasonable to say that none of the five variables Height, Chin, Forearm, Calf and Pulse contribute to the prediction/explanation of systolic blood pressure.
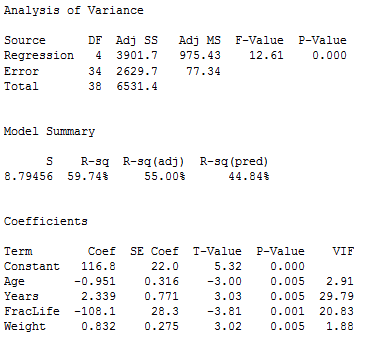
The full model includes all nine variables; SSE(full) = 2172.58, the full error df = 29, and MSE(full) = 74.92 (we get these from the Minitab results above). The reduced modelincludes only the variables Age, Years, fraclife, and Weight (which are the remaining variables if the five possibly non-significant variables are dropped). Regression results for the reduced model are given below.

We see that SSE(reduced) = 2629.7, and the reduced error df = 34. We also see that all four individual x-variables are statistically significant.
The calculation for the general linear F-test statistic is:
F=SSE(reduced) - SSE(full)error df for reduced - error df for fullMSE(full)=2629.7−2172.5834−2974.92=1.220F=SSE(reduced) - SSE(full)error df for reduced - error df for fullMSE(full)=2629.7−2172.5834−2974.92=1.220
Thus, this test statistic comes from an F5,29distribution, of which the associated p-value is 0.325 (this can be done by using Calc >> Probability Distribution >> F in Minitab). This is not at a statistically significant level, so we do not reject the null hypothesis. Thus it is feasible to drop the variables X5, X6, X7, X8, and X9 from the model.
Example: Measurements of College Students
For n = 55 college students, we have measurements (Physical.txt) for the following five variables:
Y = height (in)
X1 = left forearm length (cm)
X2 = left foot length (cm)
X3 = head circumference (cm)
X4 = nose length (cm)
The Minitab output for the full model is given below.

Notice in the output that there are also t-test results provided. The interpretations of these t-tests are as follows:
- The sample coefficients for LeftArm and LeftFoot achieve statistical significance. This indicates that they are useful as predictors of Height.
- The sample coefficients for HeadCirc and nose are not significant. Each t-test considers the question of whether the variable is needed, given that all other variables will remain in the model.
Below is a plot of residuals versus the fitted values and it seems suitable.

There is no obvious curvature and the variance is reasonably constant. One may note two possible outliers, but nothing serious.
The first calculation we will perform is for the general linear F-test. The results above might lead us to test
H0 : β3 =
β4 = 0
HA : at least one of {β3 ,
β4} ≠ 0
in the full model. If we fail to reject the null hypothesis, we could then remove both of HeadCirc and noseas predictors.
Below is the ANOVA table for the full model.

From this output, we see that SSE(full) = 238.35, with df = 50, and MSE(full) = 4.77. The reduced model includes only the two variables LeftArm and LeftFoot as predictors. The ANOVA results for the reduced model are found below.

From this output, we see that SSE(reduced) = SSE(X1 , X2) = 240.18, with df = 52, and MSE(reduced) = MSE(X1 , X2) = 4.62.
With these values obtained, we can now obtain the test statistic for testing H0 : β3 = β4 = 0:
F=SSE(X1,X2)−SSE(full)error df for reduced - error df for fullMSE(full)=240.18−238.3552−504.77=0.192F=SSE(X1,X2)−SSE(full)error df for reduced - error df for fullMSE(full)=240.18−238.3552−504.77=0.192
This value comes from an F2,50 distribution. By using Calc >> Probability Distribution >> Fin Minitab, we learn that the area to the left of F = 0.192 (with df of 2 and 50) is 0.174. The p-value is the area to the right of F, so p = 1 − 0.174 = 0.826. Thus, we do not reject the null hypothesis and it is reasonable to removeHeadCirc and nose from the model.
Next we consider what fraction of variation in Y = Height cannot be explained by X2 = LeftFoot, but can be explained by X1 = LeftArm? To answer this question, we calculate the partial R2. The formula is:
R2Y,1|2=SSR(X1|X2)SSE(X2)=SSE(X2)−SSE(X1,X2)SSE(X2)RY,1|22=SSR(X1|X2)SSE(X2)=SSE(X2)−SSE(X1,X2)SSE(X2)
The denominator, SSE(X2), measures the unexplained variation in Y when X2 is the predictor. The ANOVA table for this regression is found in below.

These results give us SSE(X2) = 347.3.
The numerator, SSE(X2)–SSE(X1, X2 ), measures the further reduction in the SSE when X1 is added to the model. Results from the earlier Minitab output give us SSE(X1, X2) = 240.18 and now we can calculate:
R2Y,1|2=SSR(X1|X2)SSE(X2)=SSE(X2)−SSE(X1,X2)SSE(X2)=347.3−240.18347.3=0.308RY,1|22=SSR(X1|X2)SSE(X2)=SSE(X2)−SSE(X1,X2)SSE(X2)=347.3−240.18347.3=0.308
Thus X1 = LeftArm explains 30.8% of the variation in Y = Height that could not be explained by X2 =LeftFoot.
‹ 6.6 - Lack of Fit
Add Answer to:
In this exercise use the Peruvian blood pressure data set, provided in the file peruvian.txt. Thi...
Suppose that we want to find a regression equation relating systolic blood pressure (y) to weight...
Suppose that we want to find a regression equation relating systolic blood pressure (y) to weight (x1), age (x2) and smoking status (0 = does not smoke, 1 = smokes less than one pack per day, 2 = smokes one or more packs per day). Use the Minitab outputs below to test whether or not the smoking status variable adds to the predictive value of a model which already contains weight and age, using α = .05. i.e., test the...
' - [2 marks] Suppose that we want to find a regression equation relating systolic blood...
 '
- [2 marks] Suppose that we want to find a regression equation relating systolic blood pressure (v) to weight (x1), age (x2) and smoking status (0 = does not smoke, 1 = smokes less than one pack per day, 2 = smokes one or more packs per day). Use the Minitab outputs below to test whether or not the smoking status variable adds to the predictive value of a model which already contains weight and age, using a =...
'
- [2 marks] Suppose that we want to find a regression equation relating systolic blood pressure (v) to weight (x1), age (x2) and smoking status (0 = does not smoke, 1 = smokes less than one pack per day, 2 = smokes one or more packs per day). Use the Minitab outputs below to test whether or not the smoking status variable adds to the predictive value of a model which already contains weight and age, using a =...
6. (textbook) An analyst fitted a regression model to predict city MPG using as predictors Length...
 6. (textbook) An analyst fitted a regression model to predict city MPG using as predictors Length (of car in inches), Width (of car in inches) and Weight (of car in pounds). a. Intuitively, what association do you expect between the explanatory variables and MPG? b. Do you see anything of concern about these variables being used as explanatory variables? Explain S c. What does the matrix plot done in class show you? Explain d. Write the null and alternative hypothesis...
6. (textbook) An analyst fitted a regression model to predict city MPG using as predictors Length (of car in inches), Width (of car in inches) and Weight (of car in pounds). a. Intuitively, what association do you expect between the explanatory variables and MPG? b. Do you see anything of concern about these variables being used as explanatory variables? Explain S c. What does the matrix plot done in class show you? Explain d. Write the null and alternative hypothesis...
Exercise 1. For this exercise use the bdims data set from the openintro package. Type ?bdims to r...
 Exercise 1. For this exercise use the bdims data set from the openintro package. Type ?bdims to read about this data set in the help menu. Of interest are the variables hgt (height in centimeters), wgt (weight in kilograms), and sex (dummy variable with 1-male, 0-female). Since ggplotO requires that a categorical variable be coded as a factor type in R, run the following code: library (openintro) bdíms$sex2 <-factor (bdins$sex, levels-c (0,1), labels=c('F', 'M')) (a) Use ggplot2 to make a...
Exercise 1. For this exercise use the bdims data set from the openintro package. Type ?bdims to read about this data set in the help menu. Of interest are the variables hgt (height in centimeters), wgt (weight in kilograms), and sex (dummy variable with 1-male, 0-female). Since ggplotO requires that a categorical variable be coded as a factor type in R, run the following code: library (openintro) bdíms$sex2 <-factor (bdins$sex, levels-c (0,1), labels=c('F', 'M')) (a) Use ggplot2 to make a...
The Minitab output shown below was obtained by using paired data consisting of weights (in lb)...
 The Minitab output shown below was obtained by using paired data consisting of weights (in lb) of 28 cars and their highway fuel consumption amounts (in mi/gal). Along with the paired sample data, Minitab was also given a car weight of 4500 lb to be used for predicting the highway fuel consumption amount. Use the information provided in the display to determine the value of the linear correlation coefficient. (Be careful to correctly identify the sign of the correlation coefficient.)...
The Minitab output shown below was obtained by using paired data consisting of weights (in lb) of 28 cars and their highway fuel consumption amounts (in mi/gal). Along with the paired sample data, Minitab was also given a car weight of 4500 lb to be used for predicting the highway fuel consumption amount. Use the information provided in the display to determine the value of the linear correlation coefficient. (Be careful to correctly identify the sign of the correlation coefficient.)...
A.) This is a small set of data provided to investigate the relationship between the age...
A.) This is a small set of data provided to investigate the relationship between the age of a lab computer and the number of service calls on it for the school year. Computer output for these data follows. The following data was reported X Age of lab computer 1 1 2 2 2 3 3 3 3 4 5 5 Y Number of repair calls 1 0 2 0 3 1 3 2 5 3 5 4 The regression equation...
Question 4 (3 points) The statsmodels ols() method is used on a cars dataset to fit...
 Question 4 (3 points) The statsmodels ols() method is used on a cars dataset to fit a multiple regression model using Quality as the response variable. Speed and Angle are used as predictor variables. The general form of this model is: Y = Bo + B. Speed+B Angle If the level of significance, alpha, is 0.10, based on the output shown, is Angle statistically significant in the multiple regression model shown above? Select one. OLS Regression Results ==================================== ========== 0.978...
Question 4 (3 points) The statsmodels ols() method is used on a cars dataset to fit a multiple regression model using Quality as the response variable. Speed and Angle are used as predictor variables. The general form of this model is: Y = Bo + B. Speed+B Angle If the level of significance, alpha, is 0.10, based on the output shown, is Angle statistically significant in the multiple regression model shown above? Select one. OLS Regression Results ==================================== ========== 0.978...
The first photo is the data I had collected in Minitab.I am confused on what the...
 The first photo is the data I
had collected in Minitab.I am confused on what the b1= to then get
the degree of freedom. I need this information to answer question
16 to plug in the right information in minitab to get t*multiplier.
Overall need help with getting the answer to #16 so then I can
continue the rest of the problems. Thanks! (also for 17 what is
S.E.)
Regression: icu versus age Simple Analysis of Variance Source DF Adj...
The first photo is the data I
had collected in Minitab.I am confused on what the b1= to then get
the degree of freedom. I need this information to answer question
16 to plug in the right information in minitab to get t*multiplier.
Overall need help with getting the answer to #16 so then I can
continue the rest of the problems. Thanks! (also for 17 what is
S.E.)
Regression: icu versus age Simple Analysis of Variance Source DF Adj...
. The data set below contains information about the gasoline mileage performance for 32 au- tomob...
 please answer the following using the r code provided
. The data set below contains information about the gasoline mileage performance for 32 au- tomobiles. We are interested in developing a model to predict the miles per gallon () using related predictor variables. The variables in the study are Dependent variable: Miles per gallon (v) Independent variables: ri horsepower (ft-lb) ra: torque (ft-lb) r: horsepower+torque (ft-lb) rs: carburetor (barrels) (a) We first start by fitting a model using y and...
please answer the following using the r code provided
. The data set below contains information about the gasoline mileage performance for 32 au- tomobiles. We are interested in developing a model to predict the miles per gallon () using related predictor variables. The variables in the study are Dependent variable: Miles per gallon (v) Independent variables: ri horsepower (ft-lb) ra: torque (ft-lb) r: horsepower+torque (ft-lb) rs: carburetor (barrels) (a) We first start by fitting a model using y and...
Exercise 2. [Data analysis, requires R] For this questions use the bac data set from the...
 Exercise 2. [Data analysis, requires R] For this questions use the bac data set from the openintro library. To access this data set first install the package using install.packages ("openintro") (this only needs to be done once). Then load the pack- age into R with the command library(openintro). You can read about this data set in the help menu by entering the command ?openintro or help(openintro). Many people believe that gender, weight, drinking habits, and many other factors are much...
Exercise 2. [Data analysis, requires R] For this questions use the bac data set from the openintro library. To access this data set first install the package using install.packages ("openintro") (this only needs to be done once). Then load the pack- age into R with the command library(openintro). You can read about this data set in the help menu by entering the command ?openintro or help(openintro). Many people believe that gender, weight, drinking habits, and many other factors are much...
 '
- [2 marks] Suppose that we want to find a regression equation relating systolic blood pressure (v) to weight (x1), age (x2) and smoking status (0 = does not smoke, 1 = smokes less than one pack per day, 2 = smokes one or more packs per day). Use the Minitab outputs below to test whether or not the smoking status variable adds to the predictive value of a model which already contains weight and age, using a =...
'
- [2 marks] Suppose that we want to find a regression equation relating systolic blood pressure (v) to weight (x1), age (x2) and smoking status (0 = does not smoke, 1 = smokes less than one pack per day, 2 = smokes one or more packs per day). Use the Minitab outputs below to test whether or not the smoking status variable adds to the predictive value of a model which already contains weight and age, using a =...
 6. (textbook) An analyst fitted a regression model to predict city MPG using as predictors Length (of car in inches), Width (of car in inches) and Weight (of car in pounds). a. Intuitively, what association do you expect between the explanatory variables and MPG? b. Do you see anything of concern about these variables being used as explanatory variables? Explain S c. What does the matrix plot done in class show you? Explain d. Write the null and alternative hypothesis...
6. (textbook) An analyst fitted a regression model to predict city MPG using as predictors Length (of car in inches), Width (of car in inches) and Weight (of car in pounds). a. Intuitively, what association do you expect between the explanatory variables and MPG? b. Do you see anything of concern about these variables being used as explanatory variables? Explain S c. What does the matrix plot done in class show you? Explain d. Write the null and alternative hypothesis...
 Exercise 1. For this exercise use the bdims data set from the openintro package. Type ?bdims to read about this data set in the help menu. Of interest are the variables hgt (height in centimeters), wgt (weight in kilograms), and sex (dummy variable with 1-male, 0-female). Since ggplotO requires that a categorical variable be coded as a factor type in R, run the following code: library (openintro) bdíms$sex2 <-factor (bdins$sex, levels-c (0,1), labels=c('F', 'M')) (a) Use ggplot2 to make a...
Exercise 1. For this exercise use the bdims data set from the openintro package. Type ?bdims to read about this data set in the help menu. Of interest are the variables hgt (height in centimeters), wgt (weight in kilograms), and sex (dummy variable with 1-male, 0-female). Since ggplotO requires that a categorical variable be coded as a factor type in R, run the following code: library (openintro) bdíms$sex2 <-factor (bdins$sex, levels-c (0,1), labels=c('F', 'M')) (a) Use ggplot2 to make a...
 The Minitab output shown below was obtained by using paired data consisting of weights (in lb) of 28 cars and their highway fuel consumption amounts (in mi/gal). Along with the paired sample data, Minitab was also given a car weight of 4500 lb to be used for predicting the highway fuel consumption amount. Use the information provided in the display to determine the value of the linear correlation coefficient. (Be careful to correctly identify the sign of the correlation coefficient.)...
The Minitab output shown below was obtained by using paired data consisting of weights (in lb) of 28 cars and their highway fuel consumption amounts (in mi/gal). Along with the paired sample data, Minitab was also given a car weight of 4500 lb to be used for predicting the highway fuel consumption amount. Use the information provided in the display to determine the value of the linear correlation coefficient. (Be careful to correctly identify the sign of the correlation coefficient.)...
 Question 4 (3 points) The statsmodels ols() method is used on a cars dataset to fit a multiple regression model using Quality as the response variable. Speed and Angle are used as predictor variables. The general form of this model is: Y = Bo + B. Speed+B Angle If the level of significance, alpha, is 0.10, based on the output shown, is Angle statistically significant in the multiple regression model shown above? Select one. OLS Regression Results ==================================== ========== 0.978...
Question 4 (3 points) The statsmodels ols() method is used on a cars dataset to fit a multiple regression model using Quality as the response variable. Speed and Angle are used as predictor variables. The general form of this model is: Y = Bo + B. Speed+B Angle If the level of significance, alpha, is 0.10, based on the output shown, is Angle statistically significant in the multiple regression model shown above? Select one. OLS Regression Results ==================================== ========== 0.978...
 The first photo is the data I
had collected in Minitab.I am confused on what the b1= to then get
the degree of freedom. I need this information to answer question
16 to plug in the right information in minitab to get t*multiplier.
Overall need help with getting the answer to #16 so then I can
continue the rest of the problems. Thanks! (also for 17 what is
S.E.)
Regression: icu versus age Simple Analysis of Variance Source DF Adj...
The first photo is the data I
had collected in Minitab.I am confused on what the b1= to then get
the degree of freedom. I need this information to answer question
16 to plug in the right information in minitab to get t*multiplier.
Overall need help with getting the answer to #16 so then I can
continue the rest of the problems. Thanks! (also for 17 what is
S.E.)
Regression: icu versus age Simple Analysis of Variance Source DF Adj...
 please answer the following using the r code provided
. The data set below contains information about the gasoline mileage performance for 32 au- tomobiles. We are interested in developing a model to predict the miles per gallon () using related predictor variables. The variables in the study are Dependent variable: Miles per gallon (v) Independent variables: ri horsepower (ft-lb) ra: torque (ft-lb) r: horsepower+torque (ft-lb) rs: carburetor (barrels) (a) We first start by fitting a model using y and...
please answer the following using the r code provided
. The data set below contains information about the gasoline mileage performance for 32 au- tomobiles. We are interested in developing a model to predict the miles per gallon () using related predictor variables. The variables in the study are Dependent variable: Miles per gallon (v) Independent variables: ri horsepower (ft-lb) ra: torque (ft-lb) r: horsepower+torque (ft-lb) rs: carburetor (barrels) (a) We first start by fitting a model using y and...
 Exercise 2. [Data analysis, requires R] For this questions use the bac data set from the openintro library. To access this data set first install the package using install.packages ("openintro") (this only needs to be done once). Then load the pack- age into R with the command library(openintro). You can read about this data set in the help menu by entering the command ?openintro or help(openintro). Many people believe that gender, weight, drinking habits, and many other factors are much...
Exercise 2. [Data analysis, requires R] For this questions use the bac data set from the openintro library. To access this data set first install the package using install.packages ("openintro") (this only needs to be done once). Then load the pack- age into R with the command library(openintro). You can read about this data set in the help menu by entering the command ?openintro or help(openintro). Many people believe that gender, weight, drinking habits, and many other factors are much...
Most questions answered within 3 hours.
-
A share of common stock just paid a dividend of $1.00 If the
expected long-run growth...
asked 7 minutes ago -
The following data shows the weekly amount spent on pet hair
care products for a sample...
asked 7 minutes ago -
Tim Smunt has been asked to evaluate two machines. After some
investigation, he determines that they...
asked 10 minutes ago -
A plane takes off and climbs to 3 000 m in five minutes at an
angle...
asked 9 minutes ago -
Paclitaxel, C47H51NO14, is an anticancer compound that is
difficult to make in the lab. One reported...
asked 13 minutes ago -
For the reaction system: H2 (g) + CO2 (g) → H2O (g) + CO (g)
The...
asked 21 minutes ago -
In a random sample of 100 homes in a certain city, it is found
that 10...
asked 29 minutes ago -
A compression ignition engine is being analyzed. The
residual gas fraction is xr=0.02. The fuel-to-air
equivalence ratio is...
asked 38 minutes ago -
Which of the following is FALSE about Slow Twitch Fibers (Slow
fibers, slow oxidative fibers) compared...
asked 42 minutes ago -
Need help with drawing the mechanism of succinic anhydride to
succinimide via ammonia and heat. Kind...
asked 1 hour ago -
Steve is a sales rep for Clearwater Purification Systems, a
national manufacturer of residential water treatment...
asked 46 minutes ago -
Question 4. Using your knowledge of IS-LM, solve the following:
8
12
1+r 1+r
(a) If...
asked 51 minutes ago