The data on the below shows the number of hours a particular drug is in the...
The data on the below shows the number of hours a particular drug is in the system of 200 females. Develop a histogram of this data according to the following intervals: Follow the directions. Test the hypothesis that these data are distributed exponentially. Determine the test statistic. Round to two decimal places.
|
(sort the data first) |
| [0, 3) |
| [3, 6) |
| [6, 9) |
| [9, 12) |
| [12, 18) |
| [18, 24) |
| [24, infinity) |
| 34.7 |
| 11.8 |
| 10 |
| 7.8 |
| 2.8 |
| 20 |
| 9.8 |
| 20.4 |
| 1.2 |
| 7.2 |
| 23 |
| 1.7 |
| 2.4 |
| 10.3 |
| 18 |
| 4.9 |
| 1.5 |
| 5.6 |
| 25.5 |
| 20.2 |
| 8.3 |
| 3.1 |
| 6.5 |
| 0.5 |
| 3 |
| 23.8 |
| 20.6 |
| 2.1 |
| 11.7 |
| 6.8 |
| 6.6 |
| 14.5 |
| 28.2 |
| 3.4 |
| 13.5 |
| 2.5 |
| 8.5 |
| 21 |
| 1.4 |
| 9.6 |
| 12.8 |
| 29.4 |
| 0.9 |
| 1.8 |
| 35.9 |
| 9.3 |
| 7.5 |
| 19.6 |
| 33.6 |
| 20 |
| 0.7 |
| 1.6 |
| 9.4 |
| 8.8 |
| 6.4 |
| 7.9 |
| 7.3 |
| 14.2 |
| 14.4 |
| 7 |
| 27.6 |
| 25.8 |
| 4 |
| 6.2 |
| 14.6 |
| 1.2 |
| 32.6 |
| 4.2 |
| 13.4 |
| 15.3 |
| 27.9 |
| 6.6 |
| 8.8 |
| 0.8 |
| 7.6 |
| 8.9 |
| 4.7 |
| 18.8 |
| 29.7 |
| 6.2 |
| 7.2 |
| 14.3 |
| 11.5 |
| 1 |
| 11.4 |
| 19.4 |
| 8.9 |
| 22 |
| 2.2 |
| 4.5 |
| 28.8 |
| 8.7 |
| 9.5 |
| 6 |
| 8.4 |
| 3.2 |
| 24.3 |
| 32.6 |
| 4.3 |
| 2.3 |
| 18.4 |
| 0.4 |
| 27 |
| 7.4 |
| 8.6 |
| 18.2 |
| 12.1 |
| 8 |
| 19.8 |
| 8.2 |
| 10.1 |
| 7.5 |
| 7.1 |
| 3.5 |
| 16.2 |
| 10.6 |
| 10.5 |
| 5.4 |
| 3.9 |
| 1.9 |
| 24.9 |
| 8.5 |
| 19.2 |
| 3.7 |
| 25.2 |
| 6.7 |
| 5.1 |
| 13.7 |
| 18.6 |
| 3.6 |
| 30.4 |
| 10.2 |
| 3.8 |
| 3.3 |
| 6.1 |
| 2.7 |
| 14.1 |
| 0.1 |
| 5.7 |
| 0.7 |
| 1 |
| 7.9 |
| 8.3 |
| 6.9 |
| 4.6 |
| 9.1 |
| 26.4 |
| 6.3 |
| 7.4 |
| 19 |
| 16.2 |
| 14.7 |
| 28.5 |
| 6.4 |
| 8.7 |
| 5.8 |
| 7.8 |
| 27.3 |
| 8.2 |
| 7.9 |
| 6.3 |
| 29.7 |
| 0.3 |
| 6.9 |
| 8.1 |
| 8 |
| 5.3 |
| 9.9 |
| 2 |
| 0.8 |
| 4.1 |
| 7 |
| 31.5 |
| 8.1 |
| 17.9 |
| 0.2 |
| 7.1 |
| 20.8 |
| 4.4 |
| 1.1 |
| 6.5 |
| 7.6 |
| 5.9 |
| 14.6 |
| 5.2 |
| 6.7 |
| 2.6 |
| 26.1 |
| 12.5 |
| 6.8 |
| 29.1 |
| 6.1 |
| 9 |
| 9.2 |
| 15.3 |
| 10.4 |
| 11.6 |
| 30.4 |
| 35.9 |
| 6.5 |
Homework Answers
Get the counts in the excel as below
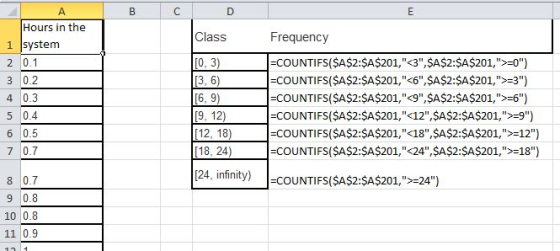
Get the follwing frequency distribution
| Class | Frequency |
| [0, 3) | 30 |
| [3, 6) | 27 |
| [6, 9) | 56 |
| [9, 12) | 21 |
| [12, 18) | 19 |
| [18, 24) | 20 |
| [24, infinity) | 27 |
plot the histogram using the bar graphs as below

We want to test the hypothesis that these data are distributed exponentially
Let X be the the number of hours a particular drug is in the
system in females. Let X has an exponential distribution with
parameter  and mean
and mean  and cdf is
and cdf is
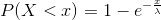
The sample mean is an unbiased MLE estimator of the mean of an exponential distribution. Hence the parameter can be estimated as
 where
where  hours is the sample mean of the 200 observations
hours is the sample mean of the 200 observations
We want to test the hypotheses
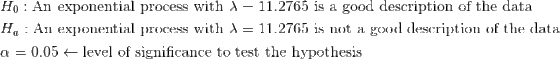
The frequency distribution gives us the observed frequency

we need to find the frequency expected if the data were exponentially distributed.
First we find the probability that X is between the each class interval.
the probability that X is between 2 intervals [a,b) is
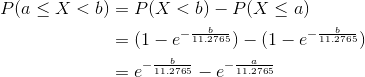
The expected frequency of the class is 
For example for Class [0,3) the probability is

The expected frequency for this class is 
For the last class [24,infty) the probability is

and the expected frequency for the last class is

Finally we get the chi-square test statistics as
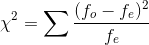
All the above calculations are in the following excel table
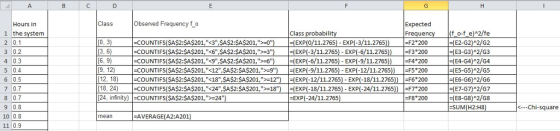
The values are
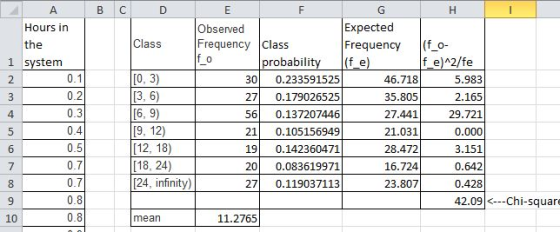
The test statistics is 42.09
Since we used the sample to estimate the parameter of exponential distribution, the degrees of freedom is k-1-1 = 7-1-1 = 5
The critical value for ch-square distribution for 0.05 level of significance is 11.070. Since the test statistics is greater than the critical value, we reject the null hypothesis.
We conclude, there is no sufficient evidence to the the hypothesis that these data are distributed exponentially
Add Answer to:
The data on the below shows the number of hours a particular
drug is in the...
The data table contains waiting times of customers at a bank, where customers enter a single...
The data table contains waiting times of customers at a bank, where customers enter a single waiting line that feeds three teller windows. Test the claim that the standard deviation of waiting times is less than 2.4 minutes, which is the standard deviation of waiting times at the same bank when separate waiting lines are used at each teller window. Use a significance level of 0.01. Complete parts (a) through (d) below. Customer Waiting Times (in minutes) 7.5 6.5 9.2...
Customer Waiting Times (in minutes) 7.4 6.9 6.9 6.8 7.4 6.6 7.7 6.5 7.2 7.9 8.7...
 Customer Waiting Times (in minutes) 7.4 6.9 6.9 6.8 7.4 6.6 7.7 6.5 7.2 7.9 8.7 7.2 7.4 7.9 6.9 6.7 8.9 7.1 7.6 6.1 7.2 7.6 7.3 5.9 7.3 6.8 6.7 6.9 7.8 7.4 6.8 6.9 6.1 6.4 5.3 7.7 7.7 7.8 7.5 6.3 7.6 7.1 6.9 8.7 7.4 6.4 6.8 7.2 8.6 6.1 7.1 6.7 7.5 7.6 7.1 8.1 7.3 7.5 7.8 6.3 The accompanying data table includes weights (in grams) of a simple random sample of 40...
Customer Waiting Times (in minutes) 7.4 6.9 6.9 6.8 7.4 6.6 7.7 6.5 7.2 7.9 8.7 7.2 7.4 7.9 6.9 6.7 8.9 7.1 7.6 6.1 7.2 7.6 7.3 5.9 7.3 6.8 6.7 6.9 7.8 7.4 6.8 6.9 6.1 6.4 5.3 7.7 7.7 7.8 7.5 6.3 7.6 7.1 6.9 8.7 7.4 6.4 6.8 7.2 8.6 6.1 7.1 6.7 7.5 7.6 7.1 8.1 7.3 7.5 7.8 6.3 The accompanying data table includes weights (in grams) of a simple random sample of 40...
The distribution above is
Given the following data set: 5.5 5.7 5.8 5.9 6.1 6.1 6.3 6.4 6.5 6.6 6.7 6.7 6.7 6.9 7.0 7.0 7.0 7.1 7.2 7.2 7.4 7.5 7.7 7.7 7.8 8.0 8.1 8.1 8.3 8.7 The distribution above is a. Pareto b. Left Skewed c. Symmetric d. Cannot be determined e. Right Skewed
1. The numbers below represent heights (in feet) of 3-year old elm trees. 5.1, 5.5, 5.8,...
1. The numbers below represent heights (in feet) of 3-year old elm trees. 5.1, 5.5, 5.8, 6.1, 6.2, 6.4, 6.7, 6.8, 6.9, 7.0, 7.2, 7.3, 7.3, 7.4, 7.5, 7.7, 7.9, 8.1, 8.1, 8.2, 8.3, 8.5, 8.6, 8.6, 8.7, 8.7, 8.9, 8.9, 9.0, 9.1, 9.3, 9.4, 9.6, 9.8, 10.0, 10.2, 10.2 Using the chi-square goodness-of-fit test, determine whether the heights of 3-year old elm trees are normally distributed, at the a = .05 significance level. Also, find the p- value.
x: pH of Ground Water in 102 West Texas Wells 7.5 8.2 7.4 7.3 7.5 7.6...
x: pH of Ground Water in 102 West Texas Wells 7.5 8.2 7.4 7.3 7.5 7.6 7.9 7.7 7.8 7.0 7.6 7.9 7.7 8.2 7.4 7.6 7.4 7.6 7.2 7.1 7.3 7.2 7.4 7.5 7.9 8.2 7.4 7.2 7.5 7.2 7.3 7.0 7.2 7.3 7.3 7.2 7.3 7.0 8.4 7.7 7.6 7.7 7.5 7.8 7.2 7.6 8.1 7.9 7.4 8.1 8.6 7.3 8.2 7.7 8.0 7.0 8.2 7.1 7.5 8.2 7.2 7.9 8.5 7.2 7.1 7.0 7.8 7.3 7.3 7.4...
In West Texas, water is extremely important. The following data represent ph levels in ground water...
 In West Texas, water is extremely important. The following data represent ph levels in ground water for a random sample of 102 West Texas wells. A pH less than 7 Is adidic and a pH above 7 is alkaline. Scanning the data, you can see that water in this region tends to be hard (alkaline). Too high a pH means the water is unusable or needs expensive treatment to make it usable.t These data are also available for download at...
In West Texas, water is extremely important. The following data represent ph levels in ground water for a random sample of 102 West Texas wells. A pH less than 7 Is adidic and a pH above 7 is alkaline. Scanning the data, you can see that water in this region tends to be hard (alkaline). Too high a pH means the water is unusable or needs expensive treatment to make it usable.t These data are also available for download at...
The data contained in the file named StateUnemp show the unemployment rate in March 2011 and...
The data contained in the file named StateUnemp show the unemployment rate in March 2011 and the unemployment rate in March 2012 for every state.† State Unemploy- ment Rate March 2011 Unemploy- ment Rate March 2012 Alabama 9.3 7.3 Alaska 7.6 7.0 Arizona 9.6 8.6 Arkansas 8.0 7.4 California 11.9 11.0 Colorado 8.5 7.8 Connecticut 9.1 7.7 Delaware 7.3 6.9 Florida 10.7 ...
how I can write this data in mhz and find the coupling constant for this data....
 how I can write this data in mhz and find the coupling
constant for this data. basically I wanna know how I can write this
data in data summary. thank you so much for your help.
I don't have those values
can you please describe it with out those values
CHE-353-DyeExpmt-MeOH 2.3 0-OH-3-56 PP- (s) Ar-Hn 6.75 p ) -2.2 -2.1 wi e ct doen AH-7-S2 Pm )2.0 AT-H-7-32 Pptri) -1.8 O-Ar-H-7.60 Ppm (d) 17 -1.9 CXAF-H 32 p--(6 1.5...
how I can write this data in mhz and find the coupling
constant for this data. basically I wanna know how I can write this
data in data summary. thank you so much for your help.
I don't have those values
can you please describe it with out those values
CHE-353-DyeExpmt-MeOH 2.3 0-OH-3-56 PP- (s) Ar-Hn 6.75 p ) -2.2 -2.1 wi e ct doen AH-7-S2 Pm )2.0 AT-H-7-32 Pptri) -1.8 O-Ar-H-7.60 Ppm (d) 17 -1.9 CXAF-H 32 p--(6 1.5...
47) The weights (in pounds) of a random sample of 32 new born babies, born at...
 47) The weights (in pounds) of a random sample of 32 new born babies, born at a particular 47) hospital are given below. Find the 95% confidence interval for the mean weight of the population of new born babies borm at this hospital. 7.5 6.4 7.1 7.1 6.8 8.6 74 6.4 74 7.0 6.0 7.8 9.0 7.3 6.5 5.8 8.4 7.6 7.2 6.5 8.5 7.1 6.3 6.9 7.0 5.9 8.3 6.6 73 77 6.4 8.2
47) The weights (in pounds) of a random sample of 32 new born babies, born at a particular 47) hospital are given below. Find the 95% confidence interval for the mean weight of the population of new born babies borm at this hospital. 7.5 6.4 7.1 7.1 6.8 8.6 74 6.4 74 7.0 6.0 7.8 9.0 7.3 6.5 5.8 8.4 7.6 7.2 6.5 8.5 7.1 6.3 6.9 7.0 5.9 8.3 6.6 73 77 6.4 8.2
Parametirc test or not: Test statistic: p-value: decision: Is There A Difference Between the Means?
Parametirc test or not:Test statistic:p-value:decision:Is There A Difference Between the Means?6.7 6.2 3.1 310.3 10 5 5.56.9 5.5 3.3 3.110.5 6.3 4.3 5.44.5 4.6 1.8 25.6 5.6 2 2.65.9 6.1 2.1 2.58 11.7 4 4.68 7.4 3.3 3.15.8 5.2 3.1 2.96 7.3 3.0 3.28.7 5.3 2.7 36 5.5 2.1 2.27.2 6.3 3.5 3.25.9 4.6 2.9 3.46 7.4 3 3.37.2 7.8 3.7 3.48.6 9.4 5.1 5.77.2 8.1 2.8 3.15.8 5.4 2.2 1.83.3 4 1.7 1.86.8 5.1 2 1.83.7 3.5 2.2 2.112...
 Customer Waiting Times (in minutes) 7.4 6.9 6.9 6.8 7.4 6.6 7.7 6.5 7.2 7.9 8.7 7.2 7.4 7.9 6.9 6.7 8.9 7.1 7.6 6.1 7.2 7.6 7.3 5.9 7.3 6.8 6.7 6.9 7.8 7.4 6.8 6.9 6.1 6.4 5.3 7.7 7.7 7.8 7.5 6.3 7.6 7.1 6.9 8.7 7.4 6.4 6.8 7.2 8.6 6.1 7.1 6.7 7.5 7.6 7.1 8.1 7.3 7.5 7.8 6.3 The accompanying data table includes weights (in grams) of a simple random sample of 40...
Customer Waiting Times (in minutes) 7.4 6.9 6.9 6.8 7.4 6.6 7.7 6.5 7.2 7.9 8.7 7.2 7.4 7.9 6.9 6.7 8.9 7.1 7.6 6.1 7.2 7.6 7.3 5.9 7.3 6.8 6.7 6.9 7.8 7.4 6.8 6.9 6.1 6.4 5.3 7.7 7.7 7.8 7.5 6.3 7.6 7.1 6.9 8.7 7.4 6.4 6.8 7.2 8.6 6.1 7.1 6.7 7.5 7.6 7.1 8.1 7.3 7.5 7.8 6.3 The accompanying data table includes weights (in grams) of a simple random sample of 40...
 In West Texas, water is extremely important. The following data represent ph levels in ground water for a random sample of 102 West Texas wells. A pH less than 7 Is adidic and a pH above 7 is alkaline. Scanning the data, you can see that water in this region tends to be hard (alkaline). Too high a pH means the water is unusable or needs expensive treatment to make it usable.t These data are also available for download at...
In West Texas, water is extremely important. The following data represent ph levels in ground water for a random sample of 102 West Texas wells. A pH less than 7 Is adidic and a pH above 7 is alkaline. Scanning the data, you can see that water in this region tends to be hard (alkaline). Too high a pH means the water is unusable or needs expensive treatment to make it usable.t These data are also available for download at...
 how I can write this data in mhz and find the coupling
constant for this data. basically I wanna know how I can write this
data in data summary. thank you so much for your help.
I don't have those values
can you please describe it with out those values
CHE-353-DyeExpmt-MeOH 2.3 0-OH-3-56 PP- (s) Ar-Hn 6.75 p ) -2.2 -2.1 wi e ct doen AH-7-S2 Pm )2.0 AT-H-7-32 Pptri) -1.8 O-Ar-H-7.60 Ppm (d) 17 -1.9 CXAF-H 32 p--(6 1.5...
how I can write this data in mhz and find the coupling
constant for this data. basically I wanna know how I can write this
data in data summary. thank you so much for your help.
I don't have those values
can you please describe it with out those values
CHE-353-DyeExpmt-MeOH 2.3 0-OH-3-56 PP- (s) Ar-Hn 6.75 p ) -2.2 -2.1 wi e ct doen AH-7-S2 Pm )2.0 AT-H-7-32 Pptri) -1.8 O-Ar-H-7.60 Ppm (d) 17 -1.9 CXAF-H 32 p--(6 1.5...
 47) The weights (in pounds) of a random sample of 32 new born babies, born at a particular 47) hospital are given below. Find the 95% confidence interval for the mean weight of the population of new born babies borm at this hospital. 7.5 6.4 7.1 7.1 6.8 8.6 74 6.4 74 7.0 6.0 7.8 9.0 7.3 6.5 5.8 8.4 7.6 7.2 6.5 8.5 7.1 6.3 6.9 7.0 5.9 8.3 6.6 73 77 6.4 8.2
47) The weights (in pounds) of a random sample of 32 new born babies, born at a particular 47) hospital are given below. Find the 95% confidence interval for the mean weight of the population of new born babies borm at this hospital. 7.5 6.4 7.1 7.1 6.8 8.6 74 6.4 74 7.0 6.0 7.8 9.0 7.3 6.5 5.8 8.4 7.6 7.2 6.5 8.5 7.1 6.3 6.9 7.0 5.9 8.3 6.6 73 77 6.4 8.2
Most questions answered within 3 hours.
-
A mixture of nitrogen and carbon
dioxide gases, in a 9.86 L flask at
40 °C,...
asked 12 minutes ago -
just another way of saying good target marketing and
understanding customer needs? Why or why not?
asked 1 hour ago -
Consider the quantum number sets listed below.
What is the name of the smallest element for...
asked 2 hours ago -
In python,write a function nameSet(first, last) that takes a
person's first and last names as input,...
asked 5 hours ago -
How do you think we should value management? Specifically how
might we try to determine MRPL...
asked 4 hours ago -
Suppose the Central Bank of Turkey starts to pay
interest on reserves. Under what circumstances this...
asked 5 hours ago -
For Bergson the concept of Being contains less reality than does
the concept of Becoming. True...
asked 6 hours ago -
What is the hydroxide ion concentration, [OH-], in a solution
with a hydronium ion concentration, [H3O+]...
asked 6 hours ago -
What species is the reducing agent in the following
equation?
Mg(s) + 2HCl (aq) --> MgCl2(aq)...
asked 6 hours ago -
A 50g ice cube is taken out of a freezer at 0 degrees Celsius
and put...
asked 8 hours ago -
How do ratios help you determine trends? What specific
information do managers look at? Is there...
asked 8 hours ago -
A wavelength of 514 nm is used to find an unknown diffraction
grating. If the separation...
asked 8 hours ago